Мониторинг RAID в Zabbix
Сб, 01/28/2017 – 08:55 — Crazy Script
Сегодня я расскажу как настроить мониторинг Raid – массива на серверах IBM с помощью системы мониторинга Zabbix.
IBM использует контроллеры LSI, у и них есть своя утилита для администрирования RAID-контроллера – MegaCli. Для установки нужно добавить репозиторий в ваш sources.list:
открываем /etc/apt/sources.list и добавляем строку:
deb http://hwraid.le-vert.net/debian jessie main
После чего устанавливаем как обычно:
apt-get update && apt-get upgrade
apt-get install megacli
Проверяем установку:
Если вывод примерно такой, значит установка прошла успешно:
MegaCLI SAS RAID Management Tool Ver 8.07.14 Dec 16, 2013
(c)Copyright 2013, LSI Corporation, All Rights Reserved.
Exit Code: 0x00
Теперь на клиентской машине, с установленным агентом zabbix в файл конфигурации /etc/zabbix/zabbix_agentd.conf добавляем строку:
UserParameter=custom.lsi.status,megacli -LDInfo -Lall -aAll | grep State | grep -vc Optimal
Значения параметров:
custom.lsi.status – имя пользовательского параметра, его мы будем использовать в шаблоне при создании элемента данных (Item).
-LDInfo -Lall -aAll – отображаем все логические устройства всех контроллеров
grep State | grep -vc Optimal – выполняем подсчет всех массивов со статусом отличным от «Optimal».
Проверяем:
# zabbix_agentd -t custom.lsi.status
custom.lsi.status [t|0]
Все работает.
Пример создания триггера в Zabbix
Создадим триггер отслеживания состояния массивов на примере LSI.
- Создаем шаблон Configuration → Templates → Create template, задаем имя и добавляем в группу Templates.
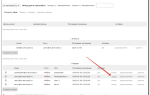
- В шаблоне открываем вкладку Items и создаем элемент. Указываем ключ(имя пользовательского параметра в zabbix-агенте – в нашем случае custom.lsi.status) и уменьшаем кол-во дней хранения значений:
- Затем переходим во вкладку Triggers (Триггеры) и создаем триггер, в поле Expression нажимаем Добавить, в появившемся окне в поле Item (Элемент данных) нажимаем Select, в появившемся окне выбираем группу Templates и только что созданный шаблон, в котором у нас единственный элемент (Item), выбираем его. В выпадающем меню Function выбираем «Last (most recent) T value is NOT N» (в рус. версии – “Последнее самое новое значение T значение not N” и проверяем, что в поле N стоит ноль, тем самым триггер будет проверять, что полученное значение от zabbix-клиента (кол-во отказавших массивов) равняется нулю, если это не так – он сработает. Вот что должно получиться (если все нормально, нажимаем Insert):
- Далее задаем имя триггера и уровень серьезности происшествия – я оценил его как Hight
- Нажимаем сохранить(Save).
Источник: http://freecoder.ru/content/zabbix-monitoring-raid
Контроль за состоянием RAID-массива | Реальные заметки Ubuntu & Windows
К системе подключены три диска.
Что делаем первым делом, когда на системе настраиваем программный RAID, правильно — обновляем систему до самого актуального состояния текущего релиза:
ekzorchik@srv-mon:~$ sudo apt-get update && sudo apt-get upgrade -y
Устанавливаю в систему пакет mdadm посредством которого и осуществляется взаимодействие с создаваемым программным RAID’ом:
ekzorchik@srv-mon:~$ sudo apt-get install mdadm -y
Присутствующие диски в системе из которых будет создавать программный RAID:
/dev/sdb,/dev/sdc,/dev/sdd — все они по 10Gb
Использовать буду RAID 5 — как раз для него нужно три диска:
ekzorchik@srv-mon:~$ sudo mdadm –create –verbose /dev/md0 –level 5 –raid-devices=3 /dev/sdb /dev/sdc /dev/sdd
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 512K
mdadm: size set to 10477056K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
Отобразить результирующую по текущей конфигурации: — файл /etc/mdadm/mdadm.conf
ekzorchik@srv-mon:~$ sudo mdadm –detail –scan
ARRAY /dev/md0 metadata=1.2 spares=1 name=srv-mon:0 UUID=3e2fc6ba:17cabd34:c44ac3db:6ca217c6
Если реальная конфигурация не совпадает с той, которая записана в /etc/mdadm/mdadm.conf, то обязательно приведите этот файл в соответствие с реальной конфигурацией до перезагрузки, иначе в следующий раз массив не запустится.
Узнать текущий статус RAID—массива можно так:
ekzorchik@srv-mon:~$ sudo mdadm –detail –scan
ARRAY /dev/md0 metadata=1.2 spares=1 name=srv-mon:0 UUID=3e2fc6ba:17cabd34:c44ac3db:6ca217c6
ekzorchik@srv-mon:~$ cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdd[3] sdc[1] sdb[0]
20954112 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [UU_]
[===============>…..] recovery = 77.0% (8071800/10477056) finish=0.6min speed=59607K/sec
unused devices:<\p>
После того, как массив создан чтобы с ним можно было работать в привычном представлении: копировать файлы, создавать файлы — нужно создать на нем (массиве) файловую систему, к примеру ext4:
ekzorchik@srv-mon:~$ sudo mkfs.ext4 /dev/md0
При создание файловой системы на диске резервируется 5% свободного места. Но мы может его уменьшить используя средства утилиты tune2fs.
Теперь смонтируем раздел RAID—массива в систему:
ekzorchik@srv-mon:~$ sudo mkdir /media/shara
ekzorchik@srv-mon:~$ sudo nano /etc/fstab
/dev/md0 /media/shara ext4 defaults 0 0
ekzorchik@srv-mon:~$ sudo mount -a
ekzorchik@srv-mon:~$ df -h | grep shara
/dev/md0 20G 44M 19G 1% /media/shara
Но это еще не все, настройка не завершена полностью, т. к. система Ubuntu 12.04.5 не знает какие RAID-массивы ей нужно создавать и какие параметры для этого используется, про что я говорю, а вот — если перезагрузить систему, то система не сможет загрузиться без Вашего внимания:
ekzorchik@srv-mon:~$ sudo reboot
The disk drive for /media/shara is not ready yet or not present.
Continue to wait, or Press S to skip mounting or M for manual recovery
Нажимаем пока клавишу S: (загружаемся пропуская этап инициализиации смонтированного массива на каталог /media/shara) и из информации по RAID массиву в файл /etc/mdadm/mdadm.conf добавляем описание для системы, что мы используем программный рейд, без это информации система все так же не сможет загрузится корректно, ведь запись ей, а как читать эту запись нету:
ekzorchik@srv-mon:~$ sudo mdadm –detail –scan –verbose
ARRAY /dev/md/srv-mon:0 level=raid5 num-devices=3 metadata=1.2 name=srv-mon:0 UUID=3e2fc6ba:17cabd34:c44ac3db:6ca217c6
devices=/dev/sdb,/dev/sdc,/dev/sdd
Из этой информации приводим конфигурационный файл /etc/mdadm/mdadm.conf к виду:
ekzorchik@srv-mon:~$ sudo nano /etc/mdadm/mdadm.conf
/dev/md0 level=raid5 num-devices=3 metadata=1.2 UUID=3e2fc6ba:17cabd34:c44ac3db:6ca217c6
Не забываем сохранить внесенные изменения.
Проверяем, что перезагрузив систему — система самостоятельно загрузится без нашего участия, как и должно иметь место быть:
ekzorchik@srv-mon:~$ sudo reboot
хм странно — ситуация не изменилась хотя должна была быть, проверяю информацию по определию массива в системе:
ekzorchik@srv-mon:~$ sudo mdadm –detail –scan
mdadm: Unknown keyword /dev/md0
ARRAY /dev/md/srv-mon:0 metadata=1.2 name=srv-mon:0 UUID=3e2fc6ba:17cabd34:c44ac3db:6ca217c6
и вот что система поменяла имя массива с /dev/md0 на /dev/md/srv-mon:0 — нужно поменять обратно:
ekzorchik@srv-mon:~$ sudo mdadm -S /dev/md/srv-mon:0
mdadm: Unknown keyword /dev/md0
mdadm: stopped /dev/md/srv-mon:0
ekzorchik@srv-mon:~$ sudo mdadm -As
mdadm: Unknown keyword /dev/md0
mdadm: /dev/md/0 has been started with 3 drives.
ekzorchik@srv-mon:~$ sudo mount -a
, но что еще заметил — проделываю команды выше и все становится в нормале, а вот когда перезагрузил систему, но снова сбилось — что же делать: (на лицо не доработаки самой утилиты управления RAID-массивом), а нужно (спасибо за документацию):
ekzorchik@srv-mon:~$ sudo nano /etc/mdadm/mdadm.conf
# automatically tag new arrays as belonging to the local system
HOMEHOST srv-mon
и заново проделываем команды:
ekzorchik@srv-mon:~$ sudo mdadm -S /dev/md/srv-mon:0
mdadm: stopped /dev/md/srv-mon:0
ekzorchik@srv-mon:~$ sudo mdadm -As
mdadm: /dev/md/0 has been started with 3 drives.
ekzorchik@srv-mon:~$ sudo mount -a
Перезагружаюсь еще раз — и снова ошибка, короче просто пока массив не введен в эксплуатацию удаляю его и создам заново с именем как обозначается система:
ekzorchik@srv-mon:~$ sudo mdadm -S /dev/md/srv-mon:0
mdadm: stopped /dev/md/srv-mon:0
Затем очищаю суперблоки RAIDа на дисках из которых пытался создать массив:
ekzorchik@srv-mon:~$ sudo mdadm –zero-superblock /dev/sdb
ekzorchik@srv-mon:~$ sudo mdadm –zero-superblock /dev/sdc
ekzorchik@srv-mon:~$ sudo mdadm –zero-superblock /dev/sdd
- ekzorchik@srv-mon:~$ sudo mdadm –create –verbose /dev/md/srv-mon:0 –auto=yes –level 5 –raid-devices=3 /dev/sdb /dev/sdc /dev/sdd
- ekzorchik@srv-mon:~$ sudo bash -c “mdadm –examine –scan >> /etc/mdadm/mdadm.conf”
вот такая вот строка добавилась в /etc/mdadm/mdadm.conf
ARRAY /dev/md/0 metadata=1.2 UUID=310c2489:de03df76:b8a3640f:4a11a75a name=srv-mon:0
- ekzorchik@srv-mon:~$ sudo update-initramfs -u
update-initramfs: Generating /boot/initrd.img-3.13.0-32-generic
Создаю файловую систему на /dev/md0:
- ekzorchik@srv-mon:~$ sudo mkfs.ext4 /dev/md0
В файл: /etc/fstab добавляю строку монтирования RAID—массива:
/dev/md0 /media/shara ext4 defaults,rw 0 0
После перезагружаюсь:
- ekzorchik@srv-mon:~$ sudo reboot
и вот теперь все хорошо, система загрузилась, массив доступен, ошибок нет.
Дальше нужно активировать и проверить работу контроля состояния RAID массива с помощью оповещения по почте, в данную информацию должно включаться:
Информация о состоянии дискового массива (Вышел диск, проблемы с диском)
За оповещение по почте буду использовать уже полюбившийся агент MTA ssmtp, а текий postfix удалю (ставился совместно с mdadm):
ekzorchik@srv-mon:~$ sudo apt-get remove postfix -y
Устанавливаю MTA агент — ssmtp:
ekzorchik@srv-mon:~$ sudo apt-get install ssmtp mailutils -y
ekzorchik@srv-mon:~$ sudo nano /etc/ssmtp/ssmtp.conf
mailhub = smtp.yandex.ru:465
AuthUser=ekzorchik@ekzorchik.ru
AuthPass=
rewriteDomain=ekzorchik.ru
UseTLS=YES
FromLineOvveride=yes
Root=postmaster
Теперь разрешаем кому можно будет из консоли отправлять почту:
ekzorchik@srv-mon:~$ sudo nano /etc/ssmtp/revaliases
root:ekzorchik@ekzorchik.ru:smtp.yandex.ru:465
ekzorchik:ekzorchik@ekzorchik.ru:smtp.yandex.ru:465
Теперь в конфигурационном файле MDADM адрес на который следует отправлять уведомления:
ekzorchik@srv-mon:~$ sudo nano /etc/mdadm/mdadm.conf
#MAILADDR root
MAILADDR alexander.ollo@nemdom.ru
Сохраняем внесенные изменения и перезапускаю сервис:
ekzorchik@srv-mon:~$ sudo /etc/init.d/mdadm restart
* Stopping MD monitoring service mdadm —monitor [ OK ]
* Starting MD monitoring service mdadm —monitor
Проверяем, что уведомления отсылаются, для это запускаем команду:
ekzorchik@srv-mon:~$ sudo mdadm –monitor –scan –test –oneshot
если у Вас команда просто висит значит у Вас какие-то проблемы с отправкой почты из консоли, разбирайтесь с ssmtp.conf:
У меня письмо пришло
Но не запускать же предыдущую команду вручную, пусть это делает планировщик к примеру раз в шесть часов для некритичных сервером, а для критичных каждый сам определяет данное значение.
Вот таким вот образом, имея практическое знакомство со множеcтвом инструментов можно в последствии их комбинировать для расширения текущего функционала друг друга, сейчас данной заметкой я еще раз прошелся по шагам как использовать программный RAID и уведомлять меня по почте на случай каких либо проблем. На этом все, с уважением автор блога — ekzorchik.
Источник: http://www.ekzorchik.ru/2015/10/control-of-the-state-of-raid-file/
Мониторинг Smart в CentOS | Admins.kz
Записка про мониторинг S.M.A.R.T жестких дисков. В каждом современном жестком диске имеется контроллер оценки состояния диска, его называют S.M.A.R.T.
Что расшифровывается как — Self-Monitoring, Analysis and ReportingTechnology — технология самоконтроля, анализа и отчётности.
Записка рассказывает про установку утилиты «smartd» для контроля состояния HDD и отправку отчета на почту системного администратора. Также вы узнаете как контролируется состояние программного рейда массива через родную утилиту «mdadm monitor» с отправкой отчета на почтовый ящик.
Краткое содержание в краткой записки:
- Установка утилиты мониторинга SMART
- Ручная проверка SMART жесткого диска
- Настройка автоматического оповещение по почте
- Мониторинг программного массива
- Настройка отправки отчета о состоянии программного рейда
- Установка утилиты мониторинга SMART
Устанавливает пакет:
# yum install smartmontools -y
Ставим демон smartd в автозагрузку:
# chkconfig smartd on
- Ручная проверка SMART жесткого диска
Проверяем Smart имеющихся дисков в системе, находим диски которые у нас есть:
# fdisk -l | grep /dev/
Disk /dev/sdc: 1000.2 GB, 1000204886016 bytes
Disk /dev/sdb: 2000.4 GB, 2000398934016 bytes
/dev/sdb1 1 243202 1953514552+ 83 Linux
Disk /dev/sda: 160.0 GB, 160041885696 bytes
/dev/sda1 * 1 1913 15360000 83 Linux
/dev/sda2 1913 3188 10240000 83 Linux
/dev/sda3 3188 4208 8192000 82 Linux swap / Solaris
/dev/sda4 4208 19458 122497880 5 Extended
/dev/sda5 4208 19458 122496000 83 Linux
Disk /dev/sdd: 1000.2 GB, 1000204886016 bytes
Disk /dev/md0: 1000.1 GB, 1000070512640 bytes
Итого видим четыре физических диска:
Проверяем Smart первого диска sda:
# smartctl -a /dev/sda
smartctl 5.43 2012-06-30 r3573 [x86_64-linux-2.6.32-431.23.3.el6.x86_64] (local build)
Copyright (C) 2002-12 by Bruce Allen, http://smartmontools.sourceforge.net
=== START OF INFORMATION SECTION ===
Model Family: Seagate Barracuda 7200.9
Device Model: ST3160212AS
Serial Number: 9LS531ZF
Firmware Version: 3.AAE
User Capacity: 160,041,885,696 bytes [160 GB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: 7
ATA Standard is: Exact ATA specification draft version not indicated
Local Time is: Sun Aug 31 18:29:45 2014 ALMT
SMART support is: Available — device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 118 091 006 Pre-fail Always — 0
3 Spin_Up_Time 0x0003 093 093 000 Pre-fail Always — 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always — 431
5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always — 0
7 Seek_Error_Rate 0x000f 061 058 030 Pre-fail Always — 824918194338
9 Power_On_Hours 0x0032 070 070 000 Old_age Always — 26712
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always — 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always — 493
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always — 0
189 High_Fly_Writes 0x003a 088 088 000 Old_age Always — 12
190 Airflow_Temperature_Cel 0x0022 062 051 045 Old_age Always — 38 (Min/Max 38/39)
194 Temperature_Celsius 0x0022 038 049 000 Old_age Always — 38 (0 17 0 0 0)
195 Hardware_ECC_Recovered 0x001a 065 046 000 Old_age Always — 115394754
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always — 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline — 0
199 UDMA_CRC_Error_Count 0x003e 200 188 000 Old_age Always — 12
200 Multi_Zone_Error_Rate 0x0000 100 253 000 Old_age Offline — 0
202 Data_Address_Mark_Errs 0x0032 100 253 000 Old_age Always — 0
Здесь я выделил модель жесткого диска, серию, прошивку и самые основные параметры Smart которые говорят нам о здоровье диска. Если растут следующие параметры:
— число операций переназначенных секторов (5 — Reallocated_Sector)
— количество попыток раскрути дисков до рабочей скорости (10 — Spin_Retry_Count)
— температура (194 — Temperature_Celsius)
— количество секторов являющимися кандидатами на замену (197 — Current_Pending_Sector)
это не хорошо, про первый параметр можно сказать что это наши Bad block — плохие сектора, если меняется второй параметр — значить имеет быть механическая проблема, что тоже страшно.
Третий — это как традиция :), а вот четвертый говорит нам, что у вас скоро будут новые бед сектора. Желательно сделать резервное копирование, а то гром грянет.
Если это софтовый рейд, то надо заменить жесткий диск в массиве.
Хотя нормальный человек настраивает резервное копирование и не сильно боится таких проблем.
И еще, если у вас растет значение UDMA_CRC_Error_Count — значит надо поменять шлейф. На жестких дисках WD бывает растет Load_Cycle_Count — полезно будет и его мониторить. На Samsung’ах может расти 200 Multi_Zone_Error_Rate, вообщем смотрите детальный отчет S.M.A.R.T., есть вероятность, что на работу влияют и другие атрибуты отчета само-тестирования.
- Настройка автоматического оповещение по почте
Рассмотрим простую отправку отчетов через почтовую утилиту mail.
Откроем /etc/crontab и впишем туда строчку мониторинга smart двух дисков sda и sdb:
0 8 * * * (/usr/sbin/smartctl -a /dev/sda; /usr/sbin/smartctl -a /dev/sdb;) | mail -s «ServerName SMART report» root
Теперь на почту root будет приходить отчет о смарт двух дисков.
Второй способ православный.
Открываем файл /etc/smartd.conf
# vi /etc/smartd.conf
И добавляем сточки:
/dev/sda -I 194 -W 4,45,55 -R 5 -R 10 -R 197 -m admin@example.com
/dev/sdb -I 194 -W 4,45,55 -R 10 -R 197 -m admin@example.com
Здесь:
— мониторим два диска sda и sdb.
-I 194 -W 4,45,55 — это мониторинг температуры, если она станет выше на 4 градуса или превысит 45 градусов.
-R 5 — мониторинг параметра Reallocated_Sector, если он изменится придет отчет
-R 10 — мониторинг параметра Spin_Retry_Count, если он изменится придет отчет
-R 197 — мониторинг параметра Current_Pending_Sector, если он изменится придет отчет
— -m admin@example.com — почтовый адрес администратора
Перезапускаем демон smartd:
# service smartd restart
- Мониторинг программного массива
Чтобы проверить целостность массива в ручную, введите команду:
# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdd[1] sdc[0]
976631360 blocks super 1.2 [2/2] [UU]
unused devices:<\p>
Здесь главное это:
— два диска sdd и sdc которые в массиве. Если будете видеть только один диск, это должно вас насторожить.
— значок [UU], который символизирует что не один диск не выпал из массива, и два диска влюблены в друг друга как муж и жена в первый год совместной жизни.
Вот пример отчета со сбойным жестким диском:
Personalities : [raid1]
md0 : active raid1 sdb2[1](F) sda2[0]
242149184 blocks super 1.0 [2/1] [U_]
bitmap: 2/2 pages [8KB], 65536KB chunk
unused devices:<\p>
Как видим, здесь пропала одна буква U в квадратных скобках и появилось буква F (Failed). Жесткий диск в программном массиве «умер».
- Настройка отправки отчета о состоянии программного рейда
Отправим для начала тестовый отчет пользователю root:
# cat /proc/mdstat | mail -s «ServerName MD reports» root
После этой команды на почту админа должен придти отчет о здоровье массива.
Чтобы такой отчет отправлялся каждый день, потребуется сделать следующее:
# vi /etc/crontab
0 8 * * * (cat /proc/mdstat) | mail -s «ServerName MD report» root
# vi /etc/sysconfig/mdcheck.sh
cat /proc/mdstat | mail -s «Name_Server MD report» admin@example.com
(/usr/sbin/smartctl -a /dev/sda; /usr/sbin/smartctl -a /dev/sdb; /usr/sbin/smartctl -a /dev/sdc; /usr/sbin/smartctl -a /dev/sdd;) | mail -s «Server_Server SMART report» admin@example.com
# chmod +x /etc/sysconfig/mdcheck.sh
# vi /etc/crontab
0 8 * * * /etc/sysconfig/mdcheck.sh
Другой способ отправки отчета о программном рейде:
Вписываем адрес куда слать отчет
# echo «MAILADDR admin@example.com»>>/etc/mdadm.conf
# /etc/init.d/mdmonitor restart
Отправляем тестовый отчет
# mdadm -Fs1t
Как стало ясно — в CentOS состояние S.M.A.R.T. мониторится через утилиту «smartd», она предоставляет детальный отчет со всеми атрибутами. При желании этот отчет отправляется на почту системного администратора.
Чтобы не читать каждый день полный отчет, у этой программы имеется возможность задействования триггеров, то есть отчет отправляется на электронный ящик только тогда, когда какой нибудь из важных атрибутов поменялся. Если вы используете программный рейд массив, у вас есть возможность мониторинга состояния массива через утилиту «mdadm monitor».
Она также умеет слать отчеты на почтовый ящик как и утилита «smartd». Комбинируя возможности этих двух утилит, мы получаем неплохой инструмент для контроля состояния наших жестких дисков.
Источник: http://www.admins.kz/monitoring-smart-v-centos.html
mdadm | Шпаргалки админа
ВАЖНО перед любыми операциями на хранилище убедитесь что бэкапы актуальны и исправны.
Сначала смотрим состояние массива, важно чтоб не шла синхронизация либо пересборка..
(я сделал ошибку, диск сбойнул и электричество выключили, я поменял физически диск и потом пытался собрать массив, что стоило мне немного нервов, надо было дождаться восстановления массива(а диск что вылетел пометить как сбойный), а уже потом идти менять диск.)
вот например
# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] md0 : active raid6 sdc1[8] sde1[7] sdg1[5] sdf1[2] sdd1[6] 5860147200 blocks super 1.2 level 6, 512k chunk, algorithm 2 [5/5] [UUUUU] [=================>…] resync = 88.6% (1732051884/1953382400) finish=38.6min speed=95562K/sec
unused devices:
если такого нет, то помечаем диск сбойным
mdadm –manage /dev/md0 –fail /dev/sda1
затем удаляем его из массива
mdadm –manage /dev/md0 –remove /dev/sda1
выключаем сервер, меняем диск, новый диск перед добавлением в массив надо подготовить
а именно, копируем на него таблицу разделов с уже имеющего в рейде диска
sfdisk -d /dev/sdb | sfdisk /dev/sda
И добавляем заменённый диск в массив
mdadm –manage /dev/md0 –add /dev/sda1
после чего автоматически начнётся пересборка массива.
Расширение массива Так получилось, что у меня массив состоял из дисков по 1.5ТБ но потом их перестали выпускать, и я менял диски на 2ТБ, но они не использовались по полной…
в итоге остался один диск на 1.5ТБ, решено его заменить на 2ТБ и расширить массив.
также перед началом смотрим что массив наш исправен, если всё ок то начинаем
mdadm –grow /dev/md0 –size=max
Автоматически начинается пересборка массива, у меня началась с 75%
вот что было до команды
# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Mon Mar 11 11:32:41 2013 Raid Level : raid6 Array Size : 4395018240 (4191.42 GiB 4500.50 GB) Used Dev Size : 1465006080 (1397.14 GiB 1500.17 GB) Raid Devices : 5
Total Devices : 5
вот что стало после
# mdadm -D /dev/md0 /dev/md0: Version : 1.2 Creation Time : Mon Mar 11 11:32:41 2013 Raid Level : raid6 Array Size : 5860147200 (5588.67 GiB 6000.79 GB) Used Dev Size : 1953382400 (1862.89 GiB 2000.26 GB) Raid Devices : 5
Total Devices : 5
После синхронизации дисков, нужно расширить Файловую систему предварительно выполнив проверку текущей, но
перед проверкой надо отмонтировать фс
и проверяем
если всё ок, то расширяем ФС
Следить за процессом пересборки массива удобно вот такой командой
Источник: http://www.odmin4eg.ru/tag/mdadm/
Кратко: Мониторинг S.M.A.R.T. в CentOS
Записка про мониторинг S.M.A.R.T жестких дисков. В каждом современном жестком диске имеется контроллер оценки состояния диска, его называют S.M.A.R.T.
Что расшифровывается как – Self-Monitoring, Analysis and Reporting Technology – технология самоконтроля, анализа и отчётности.
Записка рассказывает про установку утилиты “smartd” для контроля состояния HDD и автоматической отправки отчета на почту системного администратора. Также вы узнаете как контролируется состояние программного рейда массива через родную утилиту “mdadm monitor” с отправкой отчета на почтовый ящик.
Вообщем, утилита “smartd” считывает данные контроллера S.M.A.R.T. жесткого диска и формирует отчет, который потом читает ИТ-специалист. И если отчет не утешительный – много бед секторов, системный администратор предпринимает меры по замене диска на исправный.
Краткое содержание в краткой записки:
1. Установка утилиты мониторинга S.M.A.R.T.
2. Ручная проверка S.M.A.R.T. жесткого диска
3. Настройка автоматического оповещение по почте
4. Мониторинг программного массива
5. Настройка отправки отчета о состоянии программного рейда
1. Установка утилиты мониторинга S.M.A.R.T.
Устанавливает пакет:
# yum install smartmontools -y
Ставим демон smartd в автозагрузку:
# chkconfig smartd on
2. Ручная проверка S.M.A.R.T. жесткого диска
Проверяем S.M.A.R.T. имеющихся дисков в системе, находим диски которые у нас есть:
# fdisk -l | grep /dev/
Итого видим четыре физических диска:
Проверяем S.M.A.R.T. первого диска sda:
# smartctl -a /dev/sda
Здесь я выделил модель жесткого диска, серию, прошивку и самые основные параметры S.M.A.R.T. которые говорят нам о здоровье диска. Если растут следующие параметры:
– число операций переназначенных секторов (5 – Reallocated_Sector)
– количество попыток раскрути дисков до рабочей скорости (10 – Spin_Retry_Count)
– температура (194 – Temperature_Celsius)
– количество секторов являющимися кандидатами на замену (197 – Current_Pending_Sector)
– ошибки при передачи данных через кэш диска (184 – End-to-End Error)
То это не хорошо, про первый параметр можно сказать что это наши Bad block – плохие сектора, если меняется второй параметр – значить имеет быть механическая проблема (то есть хромает раскрутка дисков – умирает движок), что тоже страшно. Третий – это как традиция :), а вот четвертый говорит нам, что у вас скоро будут новые бед сектора. Желательно сделать резервное копирование, а то гром грянет. Если это софтовый рейд, то надо заменить жесткий диск в массиве.
Хотя нормальный человек настраивает резервное копирование и не сильно боится таких проблем.
И еще, если у вас растет значение UDMA_CRC_Error_Count – значит надо поменять шлейф. На жестких дисках WD бывает растет Load_Cycle_Count – полезно будет и его мониторить.
На Samsung'ах может расти 200 Multi_Zone_Error_Rate, а на Seagate'ах бывает увеличивается Runtime_Bad_Block – общее кол-во неисправимых блоков, вообщем смотрите детальный отчет S.M.A.R.T.
, есть вероятность, что на работу влияют и другие атрибуты отчета само-тестирования.
3. Настройка автоматического оповещение по почте
Рассмотрим простую отправку отчетов через почтовую утилиту mail.
Откроем /etc/crontab и впишем туда строчку мониторинга S.M.A.R.T. двух дисков sda и sdb:
Теперь на почту root будет приходить отчет о смарт двух дисков.
Второй способ православный.
Открываем файл /etc/smartd.conf
# vi /etc/smartd.conf
И добавляем сточки:
/dev/sda -I 194 -W 4,45,55 -R 5 -R 10 -R 197 -m admin@example.com
/dev/sdb -I 194 -W 4,45,55 -R 10 -R 197 -m admin@example.com
Здесь:
– мониторим два диска sda и sdb.
-I 194 -W 4,45,55 – это мониторинг температуры, если она станет выше на 4 градуса или превысит 45 градусов.
-R 5 – мониторинг параметра Reallocated_Sector, если он изменится придет отчет
-R 10 – мониторинг параметра Spin_Retry_Count, если он изменится придет отчет
-R 197 – мониторинг параметра Current_Pending_Sector, если он изменится придет отчет
– -m admin@example.com – почтовый адрес администратора
Перезапускаем демон smartd:
# service smartd restart
4. Мониторинг программного массива
Чтобы проверить целостность массива в ручную, введите команду:
# cat /proc/mdstat
Здесь главное это:
– два диска sdd и sdc которые в массиве. Если будете видеть только один диск, это должно вас насторожить.
– значок [UU], который символизирует что не один диск не выпал из массива, и два диска влюблены в друг друга как муж и жена в первый год совместной жизни.
Вот пример отчета со сбойным жестким диском:
Как видим, здесь пропала одна буква U в квадратных скобках и появилось буква F (Failed). Жесткий диск в программном массиве “умер”.
5. Настройка отправки отчета о состоянии программного рейда
Отправим для начала тестовый отчет пользователю root:
# cat /proc/mdstat | mail -s “ServerName MD reports” root
После этой команды на почту админа должен придти отчет о здоровье массива.
Чтобы такой отчет отправлялся каждый день, потребуется сделать следующее:
# vi /etc/crontab
# vi /etc/sysconfig/mdcheck.sh
# chmod +x /etc/sysconfig/mdcheck.sh
# vi /etc/crontab
Другой способ отправки отчета о программном рейде:
Вписываем адрес куда слать отчет
# echo “MAILADDR admin@example.com”>>/etc/mdadm.conf
# /etc/init.d/mdmonitor restart
Отправляем тестовый отчет
# mdadm -Fs1t
6. Заключение
Как стало ясно – в CentOS состояние S.M.A.R.T. мониторится через утилиту “smartd”, она предоставляет детальный отчет со всеми атрибутами. При желании этот отчет отправляется на почту системного администратора.
Чтобы не читать каждый день полный отчет, у этой программы имеется возможность задействования триггеров, то есть отчет отправляется на электронный ящик только тогда, когда какой нибудь из важных атрибутов поменялся. Если вы используете программный рейд массив, у вас есть возможность мониторинга состояния массива через утилиту “mdadm monitor”.
Она также умеет слать отчеты на почтовый ящик как и утилита “smartd”. Комбинируя возможности этих двух утилит, мы получаем неплохой инструмент для контроля состояния наших жестких дисков.
Источник: https://yvision.kz/post/427589
mdadm создание raid 1, raid 5
Рейд массив — RAID (redundunt array of inexpensive OR independant disks) — совокупность дисков сервера, работающих совместно и обеспечивающих избыточность по скорости записи/считывания информации или по надежности хранения данных. Для организации Raid mdadm является самым распространенным программным решением. Рассмотрим в mdadm создание массива raid 1, а также массива raid 5.
Рейды обычно реализованы аппаратно, однако часто встречаются и программные рейды. Применяются они, в частности, для хранения резервных копий данных.
Утилита позволит объединить несколько устройств в одно логическое, в процессе установки будет предложено ввести адрес электронной почты на который утилита будет отправлять сообщения в случае если программный рейд выйдет из строя.
Создаем простейший RAID 1, создание более сложных конфигураций может потребовать больше времени, однако принципы те же.
Стандартный конфигурационный файл не имеет какой-либо настроенной конфигурации, чтобы получить функционирующий программный рейд необходимо вносить необходимые директивы самостоятельно.
Трудности при работе с mdadm могут случиться при восстановлении поврежденного элемента массива, на этапе создания рейда проблем обычно не возникает.
Изменяем таблицу разделов, прежде всего просматриваем существующие разделы
Отмонтируем устройство
Начинаем работу с ним
Выводим состояние девайса на экран
Удаляем его
Вновь смотрим, что устройства не стало. Удаление обязательным шагом не является, но лучше пересоздавать устройство каждый раз вновь
Добавляем девайс
Номер партиции
Настройки по умолчанию (при желании здесь можно задать сектора, которые будут использоваться для записи данных)
[enter]
[enter]
Сменим тип партиции
По умолчанию используется код 83 — Linux, сейчас выбираем fd-linux raid auto
Просматриваем внесенные изменения
Записываем их на диск
Добавляем новый диск и проделываем с ним аналогичные операции
[enter]
[enter]
Диск не форматируем
/dev/md0 — имя логического девайса, который мы создаем
raid-devices — количество устройств в рейде
level — тип рейд массива
Просматривая содержимое файла мы можем видеть прогресс в создании рейд массива
Данный цикл будет выводить данные о процессе создания нового устройства до тех под пока процесс не завершится.
Убедимся в том, что устройство было создано успешно
Теперь /dev/md0 выглядит для системы также как любое другое системное устройство, создадим на нем файловую систему
Проверяем, что все получилось
Добавляем созданное устройство в автозагрузку
/dev/md0 /mnt/raid1 ext4 defaults defaults 0
Если в /etc/fstab (подробнее про fstab) были прописаны устройства, из которых создан программный рейд — отмонтируем их, в данном случае такое устройство одно
Используя mdadm создадим программный RAID-5
При использовании рейда 5 байты данных разделяются между дисками (первый байт пишется на диск А, второй на B, третий байт на C, вся информация записанная на первые три диска записывается на D). Таким образом реализуется защита от выхода из строя не более, чем одного жесткого диска.
Потребуется новое устройство, которое создается тем же способом, что рассматривался ранее
Вновь форматируем, монтируем устройство и размещаем данные
Читайте подробнее про утилиту fdisk, которая использовалась для работы с системными устройствами в процессе настройки
Источник: https://server-gu.ru/mdadm-raid/