Dashboard для логов Nginx в Kibana+Elasticsearch
Не так давно я рассказывал о том, как настроить ELK Stack для централизованного хранения логов. Сегодня хочу подробно рассказать о том, как создать координатную географическую карту на основе логов nginx и составить дашборд для него же. На этом дашборде очень удобно мониторить состояние веб проекта — расследовать инициденты, анализировать ошибки.
Введение
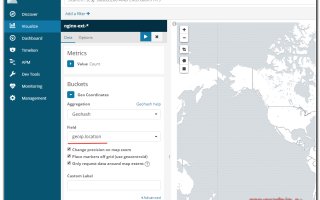
Начнем создание дашборда с самого сложного — настройки гео карты запросов. На официальном сайте есть подробный мануал на тему создания GeoIP карты. В нем вроде бы все понятно.
Никаких особых настроек не требуется. Все работает из коробки. Но у меня никак не хотело работать все то, что там описано.
Пришлось прилично поковыряться с elasticsearch и его шаблонами, чтобы разобраться в чем причина.
Все дело в том, что описанный в инструкции способ работает из коробки, только если вы используете стандартный шаблон для индексов в формате logstash-*. Скорее всего у вас будет много разных шаблонов и индексов после того, как вы запустите систему в промышленную эксплуатацию.
Основная сложность тут в том, что для работы geoip карты вам нужны в шаблоне поля с типом geo_point. После создания индекса, тип полей уже нельзя поменять.
То есть просто преобразовать данные на основе ip в координаты не сложно, это умеет делать модуль geoip в logstash. Но вот дальше вы никак не превратите координаты в виде числа в geo_point данные.
Нужно в самом начале создать шаблон с такими полями.
Надеюсь понятно объяснил
Источник: https://serveradmin.ru/dashboard-dlya-logov-nginx-v-kibana-elasticsearch/
Nginx module | Filebeat Reference [6.4]
The nginx module parses access and error logs created by the Nginx HTTP server.
When you run the module, it performs a few tasks under the hood:
- Sets the default paths to the log files (but don’t worry, you can override the defaults)
- Makes sure each multiline log event gets sent as a single event
- Uses ingest node to parse and process the log lines, shaping the data into a structure suitable for visualizing in Kibana
- Deploys dashboards for visualizing the log data
Compatibilityedit
This module requires the ingest-user-agent and ingest-geoip Elasticsearch plugins.
The Nginx module was tested with logs from version 1.10.
On Windows, the module was tested with Nginx installed from the Chocolatey repository.
Set up and run the moduleedit
Before doing these steps, verify that Elasticsearch and Kibana are running and that Elasticsearch is ready to receive data from Filebeat.
If you’re running our hosted Elasticsearch Service on Elastic Cloud, or you’ve enabled security in Elasticsearch and Kibana, you need to specify additional connection information before setting up and running the module. See Quick start: modules for common log formats for the complete setup.
To set up and run the module:
-
Enable the module:
deb and rpm:
filebeat modules enable nginx
mac:
./filebeat modules enable nginx
win:
PS > .filebeat.exe modules enable nginx
This command enables the module config defined in the modules.d directory. See Specify which modules to run for other ways to enable modules.
To see a list of enabled and disabled modules, run:
deb and rpm:
mac:
win:
PS > .filebeat.exe modules list
-
Set up the initial environment:
deb and rpm:
mac:
win:
PS > .filebeat.exe setup -e
The setup command loads the recommended index template for writing to Elasticsearch and deploys the sample dashboards (if available) for visualizing the data in Kibana. This is a one-time setup step.
The -e flag is optional and sends output to standard error instead of syslog.
-
Run Filebeat.
If your logs aren’t in the default location, see Configure the moduleedit, then run Filebeat after you’ve set the paths variable.
deb and rpm:
mac:
win:
PS > Start-Service filebeat
If the module is configured correctly, you’ll see INFO Harvester started messages for each file specified in the config.
Depending on how you’ve installed Filebeat, you might see errors related to file ownership or permissions when you try to run Filebeat modules. See Config File Ownership and Permissions in the Beats Platform Reference for more information.
-
Explore your data in Kibana:
- Open your browser and navigate to the Dashboard overview in Kibana: http://localhost:5601/app/kibana#/dashboards. Replace localhost with the name of the Kibana host. If you’re using an Elastic Cloud instance, log in to your cloud account, then navigate to the Kibana endpoint in your deployment.
- If necessary, log in with your Kibana username and password.
-
Enter the module name in the search box, then open a dashboard and explore the visualizations for your parsed logs.
If you don’t see data in Kibana, try changing the date range to a larger range. By default, Kibana shows the last 15 minutes.
Example dashboardedit
This module comes with sample dashboards. For example:
Configure the moduleedit
You can further refine the behavior of the nginx module by specifying variable settings in the modules.d/nginx.yml file, or overriding settings at the command line.
The following example shows how to set paths in the modules.d/nginx.yml file to override the default paths for access logs and error logs:
– module: nginx access: enabled: true var.paths: [“/path/to/log/nginx/access.log*”] error: enabled: true var.paths: [“/path/to/log/nginx/error.log*”]
To specify the same settings at the command line, you use:
-M “nginx.access.var.paths=[/path/to/log/nginx/access.log*]” -M “nginx.error.var.paths=[/path/to/log/nginx/error.log*]”
Variable settingsedit
Each fileset has separate variable settings for configuring the behavior of the module. If you don’t specify variable settings, the nginx module uses the defaults.
For more information, see Specify variable settings. Also see Advanced settings.
When you specify a setting at the command line, remember to prefix the setting with the module name, for example, nginx.access.var.paths instead of access.var.paths.
access log fileset settingsedit
var.pathsAn array of paths that specify where to look for the log files. If left empty, Filebeat will choose the paths depending on your operating systems.
error log filesetedit
var.pathsAn array of paths that specify where to look for the log files. If left empty, Filebeat will choose the paths depending on your operating systems.
Fieldsedit
For a description of each field in the module, see the exported fields section.
Источник: https://www.elastic.co/guide/en/beats/filebeat/6.4/filebeat-module-nginx.html
Все в сборе: настраиваем Elasticsearch + Logstash + Kibana для сбора, фильтрации и анализа логов на сервере – «Хакер»
Содержание статьи
- Стек ELK
- Установка Filebeat
- Ставим Logstash
- Ставим Elasticsearch и Kibana
- Вывод
Журналы сервисов и приложений чуть ли не единственное средство, позволяющее найти источник проблем, но обычно после установки и отладки о них просто забывают.
Современные подходы к разработке, деплою и сопровождению приложений требуют совершенно иного отношения — нужна возможность быстро найти необходимую информацию. Системы централизованного сбора и анализа журналов здесь выручают как никогда. Сегодня мы разберем, как настроить популярный ELK.
После установки сервисов логи разбросаны по каталогам и серверам, и максимум, что с ними делают, — это настраивают ротацию (кстати, не всегда). Обращаются к журналам, только когда обнаруживаются видимые сбои. Хотя нередко информация о проблемах появляется чуть раньше, чем падает какой-то сервис.
Централизованный сбор и анализ логов позволяет решить сразу несколько проблем. В первую очередь это возможность посмотреть на все одновременно. Ведь сервис часто представляется несколькими подсистемами, которые могут быть расположены на разных узлах, и если проверять журналы по одному, то проблема будет не сразу ясна.
Тратится больше времени, и сопоставлять события приходится вручную. Во-вторых, повышаем безопасность, так как не нужно обеспечивать прямой доступ на сервер для просмотра журналов тем, кому он вообще не нужен, и тем более объяснять, что и где искать и куда смотреть. Например, разработчики не будут отвлекать админа, чтобы он нашел нужную информацию.
В-третьих, появляется возможность парсить, обрабатывать результат и автоматически отбирать интересующие моменты, да еще и настраивать алерты. Особенно это актуально после ввода сервиса в работу, когда массово всплывают мелкие ошибки и проблемы, которые нужно как можно быстрее устранить.
В-четвертых, хранение в отдельном месте позволяет защитить журналы на случай взлома или недоступности сервиса и начать анализ сразу после обнаружения проблемы.
Есть коммерческие и облачные решения для агрегации и анализа журналов — Loggly, Splunk, Logentries и другие. Из open source решений очень популярен стек ELK от Elasticsearch, Logstash, Kibana.
В основе ELK лежит построенный на базе библиотеки Apache Lucene поисковый движок Elasticsearch для индексирования и поиска информации в любом типе документов.
Для сбора журналов из многочисленных источников и централизованного хранения используется Logstash, который поддерживает множество входных типов данных — это могут быть журналы, метрики разных сервисов и служб.
При получении он их структурирует, фильтрует, анализирует, идентифицирует информацию (например, геокоординаты IP-адреса), упрощая тем самым последующий анализ. В дальнейшем нас интересует его работа в связке с Elasticsearch, хотя для Logstash написано большое количество расширений, позволяющих настроить вывод информации практически в любой другой источник.
И наконец, Kibana — это веб-интерфейс для вывода индексированных Elasticsearch логов. Результатом может быть не только текстовая информация, но и, что удобно, диаграммы и графики.
Он может визуализировать геоданные, строить отчеты, при установке X-Pack становятся доступными алерты. Здесь уже каждый подстраивает интерфейс под свои задачи.
Все продукты выпускаются одной компанией, поэтому их развертывание и совместная работа не представляет проблем, нужно только все правильно соединить.
В зависимости от инфраструктуры в ELK могут участвовать и другие приложения. Так, для передачи логов приложений с серверов на Logstash мы будем использовать Filebeat. Кроме этого, также доступны Winlogbeat (события Windows Event Logs), Metricbeat (метрики), Packetbeat (сетевая информация) и Heartbeat (uptime).
Для установки предлагаются apt- и yum-репозитории, deb- и rpm-файлы. Метод установки зависит от задач и версий. Актуальная версия — 5.х. Если все ставится с нуля, то проблем нет. Но бывает, например, что уже используется Elasticsearch ранних версий и обновление до последней нежелательно.
Поэтому установку компонентов ELK + Filebeat приходится выполнять персонально, что-то ставя и обновляя из пакетов, что-то при помощи репозитория. Для удобства лучше все шаги занести в плейбук Ansible, тем более что в Сети уже есть готовые решения.
Мы же усложнять не будем и рассмотрим самый простой вариант.
Подключаем репозиторий и ставим пакеты:
$ sudo apt-get install apt-transport-https
$ wget -qO – https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add –
$ echo “deb https://artifacts.elastic.co/packages/5.x/apt stable main” | sudo tee -a /etc/apt/sources.list.d/elastic-5.x.list
$ sudo apt-get update && sudo apt-get install filebeat
В Ubuntu 16.04 с Systemd периодически всплывает небольшая проблема: некоторые сервисы, помеченные мейнтейнером пакета как enable при старте, на самом деле не включаются и при перезагрузке не стартуют. Вот как раз для продуктов Elasticsearch это актуально.
$ sudo systemctl enable filebeat
Все настройки производятся в конфигурационном файле /etc/filebeat/filebeat.yml, после установки уже есть шаблон с минимальными настройками. В этом же каталоге лежит файл filebeat.full.
yml, в котором прописаны все возможные установки. Если чего-то не хватает, то можно взять за основу его. Файл filebeat.template.json представляет собой шаблон для вывода, используемый по умолчанию.
Его при необходимости можно переопределить или изменить.
Конфигурационный файл Filebeat
Нам нужно, по сути, выполнить две основные задачи: указать, какие файлы брать и куда отправлять результат. В установках по умолчанию Filebeat собирает все файлы в пути /var/log/*.log, это означает, что Filebeat соберет все файлы в каталоге /var/log/, заканчивающиеся на .log.
filebeat.prospectors:
– input_type: log paths: – /var/log/*.log document_type: log
Учитывая, что большинство демонов хранят логи в своих подкаталогах, их тоже следует прописать индивидуально или используя общий шаблон:
– /var/log/*/*.log
Источники с одинаковым input_type, log_type и document_type можно указывать по одному в строке. Если они отличаются, то создается отдельная запись.
– paths:
– /var/log/mysql/mysql-error.log
fields: log_type: mysql-error
– paths:
– /var/log/mysql/mysql-slow.log
fields: log_type: mysql-slow
…
– paths:
– /var/log/nginx/access.log document_type: nginx-access
– paths:
– /var/log/nginx/error.log document_type: nginx-error
Поддерживаются все типы, о которых знает Elasticsearch.
Дополнительные опции позволяют отобрать только определенные файлы и события. Например, нам не нужно смотреть архивы внутри каталогов:
exclude_files: [“.gz$”]
По умолчанию экспортируются все строки. Но при помощи регулярных выражений можно включить и исключить вывод определенных данных в Filebeat. Их можно указывать для каждого paths.
include_lines: ['^ERR', '^WARN']
exclude_lines: ['^DBG']
Если определены оба варианта, Filebeat сначала выполняет include_lines, а затем exclude_lines. Порядок, в котором они прописаны, значения не имеет. Кроме этого, в описании можно использовать теги, поля, кодировку и так далее.
Теперь переходим к разделу Outputs. Прописываем, куда будем отдавать данные. В шаблоне уже есть установки для Elasticsearch и Logstash. Нам нужен второй.
output.logstash:
hosts: [“localhost:5044”]
Здесь самый простой случай. Если отдаем на другой узел, то желательно использовать авторизацию по ключу. В файле есть шаблон.
Чтобы посмотреть результат, можно выводить его в файл:
output: … file:
path: /tmp/filebeat
Нелишними будут настройки ротации:
shipper: logging: files: rotateeverybytes: 10485760 # = 10MB
Это минимум. На самом деле параметров можно указать больше. Все они есть в full-файле. Проверяем настройки:
$ filebeat.sh -configtest -e
….
Config OK
Применяем:
$ sudo systemctl start filebeat
$ sudo systemctl status filebeat
Сервис может работать, но это не значит, что все правильно. Лучше посмотреть в журнал /var/log/filebeat/filebeat и убедиться, что там нет ошибок. Проверим:
$ curl -XPUT 'http://localhost:9200/_template/filebeat' -d@/etc/filebeat/filebeat.template.json
{“acknowledged”:true}
Еще важный момент. Не всегда журналы по умолчанию содержат нужную информацию, поэтому, вероятно, следует пересмотреть и изменить формат, если есть такая возможность. В анализе работы nginx неплохо помогает статистика по времени запроса.
$ sudo nano /etc/nginx/nginx.conf log_format logstash '$remote_addr – [$time_local] $host “$request” ' '$status $body_bytes_sent “$http_referer” ' '”$http_user_agent” $request_time ' '$upstream_response_time $request_uuid'; access_log /var/log/nginx/access.log logstash;
Источник: https://xakep.ru/2017/04/06/elk-logs/
Getting started on Elasticsearch + Logstash + Kibana + Filebeat (for Nginx logs analysis)
This stories tries to cover a quick approach for getting started with Nginx logs analysis using ELK stack, Its will provide a developer as starting point of reference for using ELK stack.
It doesn't cover the details of working of these individual components.
Also I’ll try to cover certain key aspects which I found missing in the other earlier written getting started docs for same purpose.
Make sure following components are already running:
- Elasticsearch is already setup and working(on port 9200).
- Kibana is already setup and working(on port 5601).
Install/Download logstash from following link: https://www.elastic.co/guide/en/logstash/5.4/installing-logstash.html (for me downloaded logstash and extracted and did following below changes)
Create “logstash.conf” if not present(inside logstash directory) and make following changes
input {
beats {
port => 5044
}
}filter {
grok {
patterns_dir => “//logstash-6.0.0/patterns”
match => { “message” => “%{NGINXACCESS}” }
}
}output {
elasticsearch {
hosts => “localhost:9200”
manage_template => false
index => “%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}”
document_type => “%{[@metadata][type]}”
}
}
In above configuration file, variable “patterns_dir” is logstash patterns directory(patterns_dir => “//logstash-6.0.0/patterns”), find below a sample pattern(for default nginx access logs, similarly it can be extended for other logs) added in file named “nginx” on above location
NGUSERNAME [a-zA-Z.@-+_%]+
NGUSER %{NGUSERNAME}
NGINXACCESS %{IPORHOST:clientip} (?:-|(%{WORD}.%{WORD})) %{USER:ident} [%{HTTPDATE:timestamp}] “(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})” %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:referrer} %{QS:agent} %{QS:forwarder}
We can run logstash server now using following command:
./bin/logstash -f logstash.conf
Download filebeat from given link: https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-installation.html and do below changes before running:
- Making following changes in filebeat.yml file
#[1st section to be changed] Filebeat prospectors =======filebeat.prospectors:
– type: log
enabled: true
paths:
– #[2nd section to be changed] Logstash output —————–#output.logstash:
# The Logstash hosts
hosts: [“localhost:5044”]
- Run filebeat using below command:
./filebeat -e -c filebeat.yml -d “publish”
We’re almost done above command will start pushing data to elasticsearch index with name as mentioned in “logstash.conf”.
We can now use kibana to view visualizations related to data being present in elasticsearch.
Please find below certain basics of starting with Kibana dashboard related to above changes(Kibana dashboard would be accessible on URL: localhost:5601):
- Goto “Management” tab in kibana and create the index pattern, this index pattern is the elastic search index name, it takes regex expression so it can be use to fetch data from multiple indexes at once[Please find an image below related to same].
Kibana “Management” configure index pattern
- From management dashboard goto newly configured index patter and refresh field list options(otherwise these newly added fields wont be present while any analysis), it can be done by clicking find the red mark on below image
- We’re set now, click on “Discover” or “Visualize” for exploring data. From top right corner select time range(by default its 15 mins)
Hope .postlight.com”>
Источник: https://medium.com/@saurabhpresent/getting-started-on-elasticsearch-logstash-kibana-filebeat-for-nginx-logs-analysis-d567999d7846
Kibana 4, Logstash dashboard: how do I require Nginx authentication when saving but allow anonymous views?
I would like to require auth_basic nginx authentication to save all kibana 4 dashboards but allow anyone to view dashboards without authentication.
I recently installed an ELK (Elasticsearch 1.4.5, Logstash 1:1.5.2-1, and Kibana 4.1.1) stack on Ubuntu 14.04 using a DigitalOcean tutorial.
Because kibana uses browser based javascript to sends queries to elasticsearch, I'm not sure how to figure out what to secure.
DigitalOcean provides an nginx config to fully secure access to kibana 4.
FILE:/etc/nginx/sites-available/default
server { listen 80; return 301 https://logstash.nyc.3top.com;
}
server { listen 443; ssl on; ssl_certificate /etc/nginx/ssl/server.crt; ssl_certificate_key /etc/nginx/ssl/server.key; server_name logstash.example.com; access_log /var/log/nginx/kibana.access.log; auth_basic “Restricted Access”; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; }
}
Elastic provided an nginx sample config to accomplish this for Kibana 3 but not Kibana 4:
server { listen *:80 ; server_name kibana.myhost.org; access_log /var/log/nginx/kibana.myhost.org.access.log; location / { root /usr/share/kibana3; index index.html index.htm; } location ~ ^/_aliases$ { proxy_pass http://127.0.0.1:9200; proxy_read_timeout 90; } location ~ ^/.*/_aliases$ { proxy_pass http://127.0.0.1:9200; proxy_read_timeout 90; } location ~ ^/_nodes$ { proxy_pass http://127.0.0.1:9200; proxy_read_timeout 90; } location ~ ^/.*/_search$ { proxy_pass http://127.0.0.1:9200; proxy_read_timeout 90; } location ~ ^/.*/_mapping { proxy_pass http://127.0.0.1:9200; proxy_read_timeout 90; } # Password protected end points location ~ ^/kibana-int/dashboard/.*$ { proxy_pass http://127.0.0.1:9200; proxy_read_timeout 90; limit_except GET { proxy_pass http://127.0.0.1:9200; auth_basic “Restricted”; auth_basic_user_file /etc/nginx/conf.d/kibana.myhost.org.htpasswd; } } location ~ ^/kibana-int/temp.*$ { proxy_pass http://127.0.0.1:9200; proxy_read_timeout 90; limit_except GET { proxy_pass http://127.0.0.1:9200; auth_basic “Restricted”; auth_basic_user_file /etc/nginx/conf.d/kibana.myhost.org.htpasswd; } }
}
Does anyone know how to do this for Kibana 4?
Here is are my config files for elasticsearch and kibana:
/etc/elasticsearch/elasticsearch.yml
network.host: localhost
/opt/kibana/config/kibana.yml
port: 5601
host: “localhost”
elasticsearch_url: “http://localhost:9200”
elasticsearch_preserve_host: true
kibana_index: “.kibana”
default_app_id: “discover”
request_timeout: 300000
shard_timeout: 0
verify_ssl: true
bundled_plugin_ids: – plugins/dashboard/index – plugins/discover/index – plugins/doc/index – plugins/kibana/index – plugins/markdown_vis/index – plugins/metric_vis/index – plugins/settings/index – plugins/table_vis/index – plugins/vis_types/index – plugins/visualize/index
Источник: https://serverfault.com/questions/705408/kibana-4-logstash-dashboard-how-do-i-require-nginx-authentication-when-saving?rq=1
Установка ELK (ElasticSearch/Logstash/Kibana) в Unix/Linux
Для тех, кто не знает, Elastic стек (ELK стек) — это инфраструктурная программа, состоящая из нескольких компонентов, разработанных компанией Elastic.
Компоненты включают:
- Elasticsearch — Высокомасштабируемая поисковая система полнотекстового поиска и аналитики данных с открытым исходным кодом. Данная утилита позволяет быстро (а главное, — режиме реального времени) хранить, искать и анализировать большие объемы данных. Обычно он используется в качестве базового механизма / технологии, которая обеспечивает помощь приложениям со сложными функциями поиска.
- Logstash — Механизм сбора событий, который обеспечивает конвейер в реальном времени. Он может принимать данные из нескольких источников и преобразовывать их в документы JSON.
- Kibana — Утилита с открытым исходным кодом которая визуализирует работу Elasticsearch. Он используется для взаимодействия с данными, хранящимися в индексах Elasticsearch. Kibana имеет веб-интерфейс, который позволяет быстро создавать и обмениваться динамическими панелями мониторинга, отображающими изменения в запросах Elasticsearch в реальном времени.
- FileBeat — Утилита с открытым исходным кодом, которая работает в качестве агентов на серверах, для отправки различных типов оперативных данных в Elasticsearch.
И сейчас я расскажу как можно установить сие чудо.
Имеется:
- ELK — 192.168.13.195 — собственно сам сервер.
- Filebeats — 192.168.13.150 — взял одну машину в качестве примера.
Я уже описывал установку некоторых компонентов и сейчас я объединю воедино. И начну с установки компонентов.
У меня не будет сильно много нод ( я не вижу смысла в этом т.к я использую ELK для тестовых целей) и я буду использовать всего лишь 1 машину. Это не столь важно, т.к можно настроить и на нескольких. Для примеров, хватит с головой.
Как будет работать ELK? А вот скриншот того как это выглядит:
Работа elk в Unix/Linux
Установка Elasticsearch в Unix/Linux
Установка хорошо расписана в моей теме:
Установка ElasticSearch (один сервер) кластер в Unix/Linux
Если ES уже имеется в системе, пропускаем данный шаг и идем далее.
Установка Logstash в Unix/Linux
Установка хорошо расписана в моей теме:
Установка Logstash в Unix/Linux
Если Logstash уже имеется в системе, пропускаем данный шаг и идем далее.
Установка Kibana в Unix/Linux
Установка хорошо расписана в моей теме:
Установка Kibana в Unix/Linux
Если Kibana уже имеется в системе, пропускаем данный шаг и идем далее.
Настройка ELK в Unix/Linux
Пришло время настроить все это дело и запустить…
-==Настройка ElasticSearch===-
Настроим «memory lock» для различных типов ОС.
Если имеется Systemd на хосте:
# vim /usr/lib/systemd/system/elasticsearch.service
Раскомментируйте строку:
LimitMEMLOCK=infinity
Сохраните и выйдите.
Открываем еще один файл:
# vim /etc/sysconfig/elasticsearch
И раскомментируйте строку (60-я строка):
MAX_LOCKED_MEMORY=unlimited
Еще открываем один файл:
# vim /etc/elasticsearch/elasticsearch.yml
И прописываем:
bootstrap.memory_lock: true
Запускаем:
# systemctl daemon-reload
И перезапускаем Elasticsearch:
# systemctl restart elasticsearch
Если имеется SysV на хосте:
Открываем:
# vim /etc/sysconfig/elasticsearch
Раскомментируйте строку:
MAX_LOCKED_MEMORY=unlimited
Сохраните и выйдите.
Еще открываем один файл:
# vim /etc/elasticsearch/elasticsearch.yml
И прописываем:
bootstrap.memory_lock: true
И перезапускаем Elasticsearch:
# service elasticsearch restart
Если имеется Upstart на хосте:
Открываем:
# vim /etc/default/elasticsearch
Прописываем:
MAX_LOCKED_MEMORY=unlimited
Еще открываем файл:
# vim /etc/sysconfig/elasticsearch
Раскомментируйте строку:
MAX_LOCKED_MEMORY=unlimited
Сохраните и выйдите.
Еще открываем один файл:
# vim /etc/elasticsearch/elasticsearch.yml
И прописываем:
bootstrap.memory_lock: true
И перезапускаем Elasticsearch:
# service elasticsearch restart
Тестирование!
И проверяем чтобы было:
mlockall: true
Проверим, открылся ли порт:
$ netstat -natp | grep 9[2-3]00
Проверим работу:
$ curl -XGET 'localhost:9200/_nodes?filter_path=**.mlockall&pretty' $ curl -XGET 'localhost:9200/?pretty'
ИЛИ:
# curl 'http://127.0.0.1:9200/_nodes/process?pretty'
PS: Если поменяли IP, то стоит использовать именно его! И конечно же, не забываем менять все это дело в конфигурации.
Идем дальше.
-==Настройка LogStash===-
Если у вас нет DNS, то придется добавить свой собственный IP-адрес вашего ELK-сервера в subjectAltName (SAN). Это позволит вашим серверам собирать логи. И для этого, потребуется ключик.
Необходимо создать новый SSL сертификат. Сначала отредактируйте файл:
# vim /etc/pki/tls/openssl.cnf
В [ v3_ca ] разделе, прописываем:
subjectAltName = IP: 192.168.13.195
Где, localhost — Это ваш ИП адрес сервера с логстешем.
……….СПОСОБ 1 — использовать IP……….
Генерируем сертификат:
# openssl req -config /etc/pki/tls/openssl.cnf -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout /etc/pki/tls/private/logstash-forwarder.key -out /etc/pki/tls/certs/logstash-forwarder.crt
У меня это — 192.168.13.195!
……….СПОСОБ 2 — использовать доменное имя……….
# openssl req -config /etc/pki/tls/openssl.cnf -subj '/CN=ELK_domain_name/'-x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout /etc/pki/tls/private/logstash-forwarder.key -out /etc/pki/tls/certs/logstash-forwarder.crt
Где:
ELK_domain_name — Ваше доменное имя!
Перезапустим:
# service logstash restart
Идем дальше.
Настраиваем input, output, filter файлы для Logstash.
-===INPUT==-
# vim /etc/logstash/conf.d/input.conf
И он имеет следующее содержание:
input { beats { port => 5044 ssl => true ssl_certificate => “/etc/pki/tls/certs/logstash-forwarder.crt” ssl_key => “/etc/pki/tls/private/logstash-forwarder.key” } }
-===OUTPUT==-
# vim /etc/logstash/conf.d/output.conf
И он имеет следующее содержание:
output { elasticsearch { hosts => [“localhost:9200”] sniffing => true manage_template => false index => “%{[@metadata][beat]}-%{+YYYY.MM.dd}” document_type => “%{[@metadata][type]}” } }
-===FILTER==-
# vim /etc/logstash/conf.d/filter.conf
И он имеет следующее содержание:
filter { if [type] == “syslog” { grok { match => { “message” => “%{SYSLOGLINE}” } } date { match => [ “timestamp”, “MMM d HH:mm:ss”, “MMM dd HH:mm:ss” ] } } }
Проверьте файлы конфигурации Logstash:
# logstash –configtest -f /etc/logstash/conf.d/rsyslog.conf
И перезапускаем службу:
# service logstash restart
Идем дальше.
-==Настройка Kibana===-
Редактируем конфиг:
# vim /etc/kibana/kibana.yml
Приводим к такому виду:
server.host: “localhost” server.name: “ELK” elasticsearch.url: “http://localhost:9200” elasticsearch.pingTimeout: 1500 elasticsearch.requestTimeout: 30000 i18n.defaultLocale: “en”
Перезапустим:
# service nginx restart # service kibana restart
Смотрим, открылся ли порт:
# netstat -natp | grep 5601
Теперь установим nginx и настроим его как обратный прокси — это позволит заходить на кибану с публичного IP-адреса.
Подключаем EPEL:
Включить EPEL репозиторий
И выполняем:
# yum -y install nginx httpd-tools
И создаем конфиг:
# vim /etc/nginx/conf.d/kibana.conf
И прописываем:
server { listen 80; server_name elk_local; access_log /var/log/nginx/access-elk.log; error_log /var/log/nginx/error-elk.log info; auth_basic “Restricted Access”; auth_basic_user_file /etc/nginx/my_user_for_kibana; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_cache_bypass $http_upgrade; } }
PS: Для более лучшей защиты, рекомендуют использовать SSL (т.к я его сгенерировал выше, можно заюзать). Под стройкой listen 80, прописываем:
listen 443 ssl; ssl on; ssl_certificate /etc/pki/tls/certs/logstash-forwarder.crt; ssl_certificate_key /etc/pki/tls/private/logstash-forwarder.key;
Но это самоподписанный сертификат и он будет обозначен красным цветом, по этому, можно заюзать следующую статью:
Установка certbot для получения сертификата от letsencrypt в Unix/Linux
Создать новый файл аутентификации:
# htpasswd -c /etc/nginx/my_user_for_kibana kibana_admin kibana_admin_PW
Пере(запускаем) службу:
# service nginx restart
Смотрим, открылся ли порт:
# netstat -natp | grep 80
Идем дальше.
Установка Filebeat в Unix/Linux
Установка хорошо расписана в моей теме:
Установка Filebeat в Unix/Linux
Как я и говорил, он служит для отправки логов на logstash. Я на этом завершаю свою статью «Установка ELK (ElasticSearch/Logstash/Kibana) в Unix/Linux».
Источник: http://linux-notes.org/ustanovka-elk-elasticsearch-logstash-kibana-v-unix-linux/
ELK: установка Elasticsearch+Logstash+Kibana на CentOS
Elasticsearch + Logstash + Kibana – система централизованного хранения и просмотра логов.
Установка выполняется на CentOS 6.6.
Система состоит из 4-х компонентов:
- Logstash – сервер обработки входящих логов;
- Logstash Forwarder – служба передачи логов с удалённого хоста на центральный сервер Logstash (будет рассмотрен в следующей части);
- Elasticsearch – хранение логов;
- Kibana – веб-интерфейс для просмотра и анализа логов.
Продолжение – в ELK: Elasticsearch+Logstash+Kibana — добавление удалённого хоста и настройка Logstash Forwarder.
Вот как будет выглядеть схема:
Установка Java
Для работы Elasticsearch и Logstash требуется Java.
Установка описана тут>>>, только уже 8 версия:
# rpm -ivh /home/ec2-user/jdk-8u60-linux-x64.rpm Preparing… ################################# [100%] Updating / installing… 1:jdk1.8.0_60-2000:1.8.0_60-fcs ################################# [100%] Unpacking JAR files… tools.jar… plugin.jar… javaws.jar… deploy.jar… rt.jar… jsse.jar… charsets.jar… localedata.jar… jfxrt.jar… # alternatives –install /usr/bin/java java /usr/java/jdk1.8.0_60/jre/bin/java 1
Установка Elasticsearch
Добавляем ключ:
# rpm –import http://packages.elasticsearch.org/GPG-KEY-elasticsearch
Добавляем репозиторий – создаём файл /etc/yum.repos.d/elasticsearch.repo с таким содержимым:
[elasticsearch-1.4] name=Elasticsearch repository for 1.4.x packages baseurl=http://packages.elasticsearch.org/elasticsearch/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1
Устанавливаем:
# yum install elasticsearch
Редактируем файл /etc/elasticsearch/elasticsearch.yml, и ограничиваем доступ только с localhost:
… network.host: localhost …
Запускаем:
# service elasticsearch start Starting elasticsearch: [ OK ]
И добавляем в автозапуск:
# chkconfig –add elasticsearch # chkconfig –list elasticsearch elasticsearch 0:off 1:off 2:on 3:on 4:on 5:on 6:off
Установка Kibana
На находим подходящую вверсию, в данном случае – LINUX 64-BIT, загружаем:
# cd /opt/ # wget https://download.elastic.co/kibana/kibana/kibana-4.1.1-linux-x64.tar.gz # tar xfp kibana-4.1.1-linux-x64.tar.gz # mv kibana-4.1.1-linux-x64 kibana4
Редактируем файл /opt/kibana4/config/kibana.yml, и тоже ограничиваем доступ только с localhost:
… # The host to bind the server to. host: “localhost” …
Создаём init-скрипт – /etc/init.d/kibana (проверьте переменные, что бы пути совпадали с вашей системой/установкой):
#!/bin/sh # # /etc/init.d/kibana — startup script for kibana # Wolfyxvf 2015-04-16; used httpd init script as template # ### BEGIN INIT INFO # Provides: kibana # Default-Start: 2 3 4 5 # Default-Stop: 0 1 6 # Short-Description: Starts kibana # Description: Starts kibana using daemon ### END INIT INFO #configure this with wherever you unpacked kibana: KIBANA_BIN=/opt/kibana4/bin KIBANA_LOG=”/var/log/kibana.log” NAME=kibana DESC=”Kibana” PID_FOLDER=/var/run/kibana/ PID_FILE=/var/run/kibana/$NAME.pid LOCK_FILE=/var/lock/subsys/$NAME PATH=/bin:/usr/bin:/sbin:/usr/sbin:$KIBANA_BIN DAEMON=$KIBANA_BIN/kibana RETVAL=0 if [ `id -u` -ne 0 ]; then echo “You need root privileges to run this script” exit 1 fi # Source function library. . /etc/rc.d/init.d/functions if [ -f /etc/sysconfig/kibana ]; then . /etc/sysconfig/kibana fi start() { echo “Starting $DESC : ” pid=`pidofproc -p $PID_FILE kibana` if [ -n “$pid” ] ; then echo “Already running.” exit 0 else # Start Daemon if [ ! -d “$PID_FOLDER” ] ; then mkdir $PID_FOLDER fi daemon $DAEMON >> $KIBANA_LOG 2>&1 & sleep 2 pidofproc node > $PID_FILE echo RETVAL=$? [ $RETVAL = 0 ] && touch $LOCK_FILE return $RETVAL fi } stop() { echo -n $”Stopping $DESC : ” killproc -p $PID_FILE $DAEMON RETVAL=$? echo [ $RETVAL = 0 ] && rm -f $PID_FILE $LOCK_FILE } # See how we were called. case “$1″ in start) start ;; stop) stop ;; status) status -p $PID_FILE $DAEMON RETVAL=$? ;; restart) stop start ;; *) echo $”Usage: $prog {start|stop|restart|status}” RETVAL=2 esac exit $RETVAL # chmod +x /etc/init.d/kibana
Проверяем:
# service kibana status kibana is stopped
Запускаем:
# service kibana start Starting Kibana : # chkconfig –add kibana
Проверяем:
# tail /var/log/kibana.log {“name”:”Kibana”,”hostname”:”ip-172-30-0-69″,”pid”:22999,”level”:30,”msg”:”No existing kibana index found”,”time”:”2015-09-08T11:17:38.615Z”,”v”:0} {“name”:”Kibana”,”hostname”:”ip-172-30-0-69″,”pid”:22999,”level”:30,”msg”:”Listening on 127.0.0.1:5601″,”time”:”2015-09-08T11:17:38.628Z”,”v”:0}
Установка NGINX
Добавляем, если нет, репозиторий Epel:
# yum -y install epel-release
Устанавливаем NGINX и утилиты:
# yum install nginx httpd-tools
Создаём пользователя для доступа к Kibana:
# htpasswd -c /etc/nginx/htpasswd.users kibanaadmin New password: Re-type new password: Adding password for user kibanaadmin
Создаём файл настроек виртуалхоста логгера, например /etc/nginx/conf.d/logger.domain.com.conf:
server { listen 80; server_name logger.domain.com; auth_basic “Restricted Access”; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } }
Проверяем, запускаем, добавляем в автозапуск:
# nginx -t nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful # service nginx start Starting nginx: [ OK ] # chkconfig –add nginx
Теперь можно проверить URL:
Ничего не меняем, продолжаем установку.
Установка Logstash
Добавляем репозиторий – в файл /etc/yum.repos.d/logstash.repo добавляем:
[logstash-1.5] name=logstash repository for 1.5.x packages baseurl=http://packages.elasticsearch.org/logstash/1.5/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1
Устанавливаем:
# yum install logstash
Создаём SSL-сертификаты для Logstash Forwarder (будут нужны позже):
# cd /etc/pki/tls # openssl req -subj '/CN=domain.com/' -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt
Проверяем:
# ls -l certs/ | grep log -rw-r–r– 1 root root 1180 Sep 8 11:48 logstash-forwarder.crt# ls -l private/ | grep log -rw-r–r– 1 root root 1704 Sep 8 11:48 logstash-forwarder.key
Что бы Logstash имел доступ к файлам в /var/log/, которые обычно принадлежат root:root:
# getfacl /var/log/maillog getfacl: Removing leading '/' from absolute path names # file: var/log/maillog # owner: root # group: root user::rwx group::rwx other::rwx
Что приведёт к ошибкам вида:
Создаём файл defaults (в данном случае – /opt/logstash/vendor/jruby/lib/ruby/shared/rubygems/defaults/logstash, или /etc/logstash/defaults – если устанавливали другим способом), в который прописываем:
LS_GROUP=root
На этом установка необходимых компонентов закончена, можно переходить к настройке Logstash.
Настройка Logstash
Создаём файл /etc/logstash/conf.d/rsyslog.conf:
input { file { path => [ “/var/log/maillog” ] type => “syslog” start_position => “beginning” } } filter { if [type] == “syslog” { grok { match => [ “message”, “%{HOSTNAME}” ] } } } output { elasticsearch { host => localhost } }
Кратко рассмотрим что тут выполняется:
- input – обработка входящих данных, использует модуль , описывающий входящие данные; в данном случае – данные мы получаем из файла;
- filter – обработка полученных от input данных, использует модуль , определяющий какие данные будут проиндексирвоаны и добавлены (данные тип message в которых встречается шаблон %{HOSTNAME}, шаблоны описаны в файле grok-patterns, в данном случае он находится в /opt/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-0.3.0/patterns/grok-patterns);
- output – передаёт данные, прошедшие фильтр, на “backend”, в данном случае – в Elasticserch, из которого данные потом появляются в Kibana.
Проверяем синтаксис файла конфигурации:
# /opt/logstash/bin/logstash –configtest -f /etc/logstash/conf.d/rsyslog.conf
Перезапускаем Logstash:
# service logstash restart logstash started.
Настройка Kibana
Теперь можно добавить данные в веб-интерфейс.
Переходим на страницу Kibana, и добавляем новый индекс, который позволит Kibana работать с индексами Elasticsearch:
После чего переходим в Discover – и наблюдаем логи:
Продолжение – в ELK: Elasticsearch+Logstash+Kibana — добавление удалённого хоста и настройка Logstash Forwarder.
Ссылки по теме
Источник: https://rtfm.co.ua/centos-ustanovka-elasticsearch-logstash-kibana-elk/
Подключаем Kibana для хранения логов ASP.NET Core
Логи — полезные инструмент для отладки и мониторинга приложений. Только просмотр текстовых логов — дело скучное и неинтересное. Поэтому изучают логи в исключительных ситуациях.
Здесь на помощь приходят структурированные логи — когда записи хранятся не просто в виде текста, а в виде структурированных данных с разделением информации на отдельные поля.
По таким логам можно настроить фильтры, поиск, при соблюдении определенных условий — отправлять уведомления и т.д.
Инфраструктура логгирования ASP.NET Core поддерживает структурированные логи. Посмотрим как это можно использовать на примере ELK.
Elasticsearch и Kibana
Один из вариантов хранения структурированных логов — хранение их в Elasticsearch. Преимущество этого подхода заключается в том, что для этого всё уже готово — вам не нужно допиливать код для хранения данных.
ELK — это стек из трех продуктов: Elasticsearch, Logstash и Kibana:
- Elasticsearch — хранилище данных логов, позволяет искать по большим объемам данных с приемлемой скоростью.
- Kibana — удобный веб-интерфейс к хранилищу данных.
- Logstash — агрегатор, который забирает логи с жесткого диска и отправляет их в Logstash.
Веб-интерфейс Kibana. Источник: https://www.elastic.co/blog
Чтобы попробовать ELK можно использовать Docker-образ sebp/elk:
docker pull sebp/elk docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it –name elk sebp/elk
Подробнее о том, как запустить ELK внутри Docker можно почитать в документации.
После запуска Kibana будет доступна через порт 5601, а Elasticsearch API — через 9200.
Для реального проекта Elasticsearch весьма требователен к оборудванию (в частности – к RAM). Поэтому хорошим вариантом может быть использование ELK как сервиса. К счастью, таких сервисов очень много, например — раз, два, три.
Отправка в данных в Elasticsearch
Если для отправки данных используется Logstash, то всё сводится к записи логов в файл и настройки Logstash для чтения этих файлов и отправки в Elasticsearch. Альтернативным способом может быть отправка данных напрямую в Elasticsearch, минуя Logstash. Рассмотрим этот способ.
Стоит отметить, что в данном случае нам потребуется какая-нибудь библиотека для работы с Elasticsearch. Желательно также, чтобы эта библиотека была интегрирована с инфраструктурой логгирования ASP.NET Core. С учетом этого, Serilog может быть хорошим выбором: она интегрирована с ASP.NET Core и имеет провайдер для отправки логов в Elastisearch.
Установим в проект пакет Serilog, а заодно Serilog.Extensions.Logging и Serilog.Sinks.Elasticsearch.
Теперь необходимо добавить Serilog-логгер в DI-контейнер:
public class Startup { public void ConfigureServices(IServiceCollection services) { services.AddSingleton(container => new LoggerConfiguration() .ConfigureEnrichers(container) .ConfigureElk(“http://elk:9200”, Configuration.GetSection(“Logging:Elk”), container) .ConfigureSelfLog(container) .CreateLogger()); }
И в список логгинг-провайдеров:
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory) { loggerFactory.AddSerilog(services.GetService()); } }
Обратите внимание, что при конфигурировании ELK указана конфигурационная секция Logging:Elk. В ней мы указываем параметры фильтров, о которых я писал ранее.
Для данного примера конфигурационный файл может выглядеть так:
{ “Logging”: { “Console”: { “IncludeScopes”: false, “LogLevel”: { “Default”: “Debug”, “System”: “Information”, “Microsoft”: “Information” } }, “Elk”: { “IncludeScopes”: false, “LogLevel”: { “MyApp.Services”: “Information”, “MyApp.Infrastructure”: “Information” } } } }
Теперь можно воспользоваться стандартным API для логгирования и создавать записи в в ELK:
public class HomeController : Controller { private readonly ILogger _logger; public HomeController(ILogger logger) { _logger = logger; } public IActionResult Index() { _logger.LogError(“Some error occured”); return View(); } }
Однако, гораздо интереснее в таком случае писать в лог структурированную информацию. Для этого немного изменим способ логгирования:
public class HomeController : Controller { private readonly ILogger _logger; public HomeController(ILogger logger) { _logger = logger; } public IActionResult Index() { var request = …; var config = …; _logger.LogError(“Some error occured.{User}{@Request}{@Config}”, User.Identity.Name, request, config); return View(); } }
Теперь данные отправляются в ELK в структурированном виде.
Если для каждой записи в лог требуется сохранять какие-то стандартные данные (например, данные HTTP-запроса, окружения и т.д.) можно воспользоваться специальными объектами Serilog — Enricher'ами. О том, как их использовать можно почитать в документации.
Источник: https://blog.zwezdin.com/2017/asp-net-core-logging-into-kibana/