Бэдблоки, (почти)умерший хард и как мне удалось разобраться со всем этим делом
Итак, суть этой печальной истории в том, что ВНЕЗАПНО мой жесткий диск начал издеваться надо мной, когда я хотел поставить LibreOffice. После того, как система дважды перемонтировала партицию в readonly, я начал подозревать неладное. Глянул dmesg, а там! Мать моя женщина!
Ну общую суть вы, думаю поняли – покупай новый жесткий диск@копируй разделы со старого.
Но! Проблема еще была в том, что некоторые разделы УЖЕ не монтировались, по причине смерти коррупции файловой системы.
/me подумал-подумал и решил, а не попробовать ли как-то это дело замять, тем более, новый жесткий пока не входит в планы первоочерёдных покупок.
Гуугле мне подсказал парочку хороших решений, чем я незамедлительно и воспользовался.
Удивительная статья, которая мне очень сильно помогла.
Для тех, кто не в ладах с языком международного общения, могу адаптировать статью, хотите – отпишитесь в комментариях. Итак, разбор полётов, или что я сделал.
К счастью, у меня завалялась таблица разделов диска, сделанная fdisk -ul На самом деле, у меня было 10 разделов, но те три, которых здесь нет не были столь важны, как sda3+sda4(Зарезервированы под FreeBSDDragonFlyBSD, sda1(загрузочный же, ёпта!) sda7+sda5(линуксовые разделы), ну и sda6(онимэ, музыка, прочий хлам)
Первым делом, был проведён тест, на то, какие партиции умерли, а какие еще живы. К моей радости, sda1 и sda6 остались живы, но о них попозже. все остальные монтироваться НЕ ЖЕЛАЛИ, а fsck завершался с ошибкой.
я запустил smartctl -t long /dev/sda и ушел на два часа.
Через пару часов, возвратившись, я увидел сию картину smartctl -l selftest /dev/sdasmartctl version 5.38 [i686-pc-linux-gnu] Copyright (C) 2002-8 Bruce AllenHome page is http://smartmontools.sourceforge.
net/=== START OF READ SMART DATA SECTION ===SMART Self-test log structure revision number 1Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error# 1 Extended offline Completed: read failure 90% 8962 712567177# 2 Short offline Completed without error 00% 5188 –
# 3 Extended offline Aborted by host 90% 5188 –
Как видите, первая ошибка проявилась в блоке 712567177
Запускаем badblocks: badblocks -s -v -b 512 /dev/sda 712567277 712567077#-s показывает прогресс, -v увеличивает информативность, -b 512 – указывается размер блока, в данном случае – 512 байт, дальше указываем КОНЕЧНЫЙ и потом уже НАЧАЛЬНЫЙ блок, которые я выбрал из окружения в +-100 блоков к ошибочному.
И правда, выскакивают номера бэдблоков. Провел щадящий read-write тест (опция -n) – бэдблоки тоже продолжают появдяться. Далее я сделал то, что НЕ РЕКОММЕНДУЮ делать другим без полного понимания того, ЧТО они делают. badblocks -s -w -v -b 512 /dev/sda 712567277 712567077#-w – write-mode, заполнение определенными паттернами, МОЖЕТ ПОВРЕДИТЬ ДАННЫЕ. Что удивительно, после этого бэдблоки исчезли. Проведя еще несколько тестов smartctl, теперь уже с опцией -t short, я вычислил остальные бэдблоки и провел аналогичные операции. Теперь
smartctl -l selftest -d ata /dev/sdasmartctl version 5.38 [i686-pc-linux-gnu] Copyright (C) 2002-8 Bruce AllenHome page is http://smartmontools.sourceforge.net/=== START OF READ SMART DATA SECTION ===SMART Self-test log structure revision number 1Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error# 1 Short offline Completed without error 00% 8972 -# 2 Extended offline Completed: read failure 90% 8962 712567177# 3 Short offline Completed without error 00% 5188 –
# 4 Extended offline Aborted by host 90% 5188 –
Как видим, ошибок больше нет, но раз уже они появились – жди новых//уже откладываю деньги на новый хард.
Теперь о минусах такого способа. После всех манипуляций, fdisk -ul /dev/sda показал мне ПОЛНОСТЬЮ голый диск. Запускаем testdisk, находим разделы. К сожалению, sda6 не был найден. Ну ладно, мы не боимся этого.
fdisk -u /dev/sda, дальше жмём n/*новый раздел*/ дальше вводим какой тип раздела, logical или primary, потом вводим начало и конец сектора/*ну недаром же у меня была таблица разделов?*/, записываем таблицу разделов – w и выходим из fdisk -q.
пишем partprobe, чтобы ядро узнало о новом разделе, вуаля – раздел появился и он полностью жив.
Итак, любые вопросы, предложения и замечания буду рад прочитать в комментариях.
Источник: https://Kubuntu.ru/node/7514
hdd problems, failed command: READ FPDMA QUEUED
Hello!
I have a brand new computer. With a SSD device and a SATA hard drive, a Seagate Barracuda XT specifically 6Gb / s of 2TB. The latter is connected to a Marvell 9123 controller that I set AHCI mode in BIOS.
I have the OS installed on the SSD device, but when you try to read the disc 2TB gives several bugs.
I tried to change the disk to another controller and gives the same problem, I even removed the disk partition table, having the same fate.
I checked the disc for flaws from Windows with hd tune and verification tool official record, and does not give me any errors.
I have tested with kernel version 2.6.34-rc2 and it works properly with this disc.
The errors given are the following:
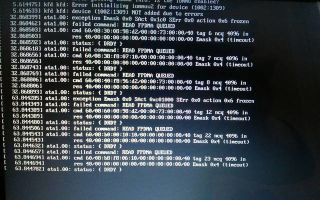
[ 9.115544] ata9: exception Emask 0x0 SAct 0xf SErr 0x0 action 0x10 frozen [ 9.115550] ata9.00: failed command: READ FPDMA QUEUED
[ 9.115556] ata9.00: cmd 60/04:00:d4:82:85/00:00:1f:00:00/40 tag 0 ncq 2048 in
[ 9.115557] res 40/00:18:d3:82:85/00:00:1f:00:00/40 Emask 0x4 (timeout) [ 9.115560] ata9.00: status: { DRDY } [ 9.115562] ata9.00: failed command: READ FPDMA QUEUED
[ 9.115568] ata9.00: cmd 60/01:08:d1:82:85/00:00:1f:00:00/40 tag 1 ncq 512 in
[ 9.115569] res 40/00:18:d3:82:85/00:00:1f:00:00/40 Emask 0x4 (timeout) [ 9.115572] ata9.00: status: { DRDY } [ 9.115574] ata9.00: failed command: READ FPDMA QUEUED
[ 9.115579] ata9.00: cmd 60/01:10:d2:82:85/00:00:1f:00:00/40 tag 2 ncq 512 in
[ 9.115581] res 40/00:18:d3:82:85/00:00:1f:00:00/40 Emask 0x4 (timeout) [ 9.115583] ata9.00: status: { DRDY } [ 9.115586] ata9.00: failed command: READ FPDMA QUEUED
[ 9.115591] ata9.00: cmd 60/01:18:d3:82:85/00:00:1f:00:00/40 tag 3 ncq 512 in
[ 9.115592] res 40/00:18:d3:82:85/00:00:1f:00:00/40 Emask 0x4 (timeout) [ 9.115595] ata9.00: status: { DRDY }
[ 9.115609] sd 8:0:0:0: [sdb] Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
[ 9.115612] sd 8:0:0:0: [sdb] Sense Key : Aborted Command [current] [descriptor] [ 9.115616] Descriptor sense data with sense descriptors (in hex): [ 9.115618] 72 0b 00 00 00 00 00 0c 00 0a 80 00 00 00 00 00 [ 9.115626] 1f 85 82 d3 [ 9.115629] sd 8:0:0:0: [sdb] Add. Sense: No additional sense information [ 9.115633] sd 8:0:0:0: [sdb] CDB: Read(10): 28 00 1f 85 82 d4 00 00 04 00 [ 9.115640] end_request: I/O error, dev sdb, sector 528843476 [ 9.115643] __ratelimit: 18 callbacks suppressed [ 9.115646] Buffer I/O error on device sdb2, logical block 317299556 [ 9.115649] Buffer I/O error on device sdb2, logical block 317299557 [ 9.115652] Buffer I/O error on device sdb2, logical block 317299558 [ 9.115655] Buffer I/O error on device sdb2, logical block 317299559
[ 9.115671] sd 8:0:0:0: [sdb] Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
[ 9.115674] sd 8:0:0:0: [sdb] Sense Key : Aborted Command [current] [descriptor] [ 9.115678] Descriptor sense data with sense descriptors (in hex): [ 9.115679] 72 0b 00 00 00 00 00 0c 00 0a 80 00 00 00 00 00 [ 9.115687] 1f 85 82 d3 [ 9.115690] sd 8:0:0:0: [sdb] Add. Sense: No additional sense information [ 9.115693] sd 8:0:0:0: [sdb] CDB: Read(10): 28 00 1f 85 82 d1 00 00 01 00 [ 9.115700] end_request: I/O error, dev sdb, sector 528843473 [ 9.115702] Buffer I/O error on device sdb2, logical block 317299553
[ 9.115707] sd 8:0:0:0: [sdb] Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
[ 9.115710] sd 8:0:0:0: [sdb] Sense Key : Aborted Command [current] [descriptor] [ 9.115714] Descriptor sense data with sense descriptors (in hex): [ 9.115716] 72 0b 00 00 00 00 00 0c 00 0a 80 00 00 00 00 00 [ 9.115723] 1f 85 82 d3 [ 9.115726] sd 8:0:0:0: [sdb] Add. Sense: No additional sense information [ 9.115729] sd 8:0:0:0: [sdb] CDB: Read(10): 28 00 1f 85 82 d2 00 00 01 00 [ 9.115736] end_request: I/O error, dev sdb, sector 528843474 [ 9.115738] Buffer I/O error on device sdb2, logical block 317299554
[ 9.115743] sd 8:0:0:0: [sdb] Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
[ 9.115746] sd 8:0:0:0: [sdb] Sense Key : Aborted Command [current] [descriptor] [ 9.115749] Descriptor sense data with sense descriptors (in hex): [ 9.115751] 72 0b 00 00 00 00 00 0c 00 0a 80 00 00 00 00 00 [ 9.115759] 1f 85 82 d3 [ 9.115762] sd 8:0:0:0: [sdb] Add. Sense: No additional sense information [ 9.115765] sd 8:0:0:0: [sdb] CDB: Read(10): 28 00 1f 85 82 d3 00 00 01 00 [ 9.115771] end_request: I/O error, dev sdb, sector 528843475 [ 9.115774] Buffer I/O error on device sdb2, logical block 317299555 [ 16.243531] sd 8:0:0:0: timing out command, waited 7s
[ 23.241557] sd 8:0:0:0: timing out command, waited 7s
lsb_release -rd Description: Ubuntu lucid (development branch) Release: 10.04
ignasi@ignasi-desktop:~$
ProblemType: Bug DistroRelease: Ubuntu 10.04 Package: yelp 2.29.5-0ubuntu3
Источник: https://bugs.launchpad.net/bugs/550559
Ubuntu 11.04 Server Crashing – failed command: READ FPDMA QUEUED
I have a new Ubuntu Server (11.04) that keeps crashing, especially during heavy disk I/O (like making a backup). It's drives are configures as a RAID 10 with 4 1TB Western Digital Caviar Black Hard Drives.
The message I'm seeing via /proc/kmsg when it crashes is, “failed command: READ FPDMA QUEUED”.
This seems like something is messed up with either the drives or the software raid is broken?
The machine was doing fine until this afternoon when it crashed during a file transfer Ever since then it's been crashing when I try to run a backup, but it's not always the same file or place each time.
How do I know if it's a software or hardware failure? How do I know if it's the SATA controller or one of the disks?
Also, all 4 drives in the array “completed without error” when I ran an extended off-line test on them.
This is the full output of /proc/kmsg from the time I rebooted until it crashed again:
[ 356.076292] type=1400 audit(1311983491.536:14): apparmor=”DENIED” operation=”open” parent=1397 profile=”/usr/lib/libvirt/virt-aa-helper” name=”/dev/dm-9″ pid=2222 comm=”virt-aa-helper” requested_mask=”r” denied_mask=”r” fsuid=0 ouid=105
[ 356.304840] type=1400 audit(1311983491.766:15): apparmor=”STATUS” operation=”profile_load” name=”libvirt-c67f4a48-2cad-6deb-d7e7-13f9c7620ad9″ pid=2223 comm=”apparmor_parser”
[ 357.002246] device vnet0 entered promiscuous mode
[ 357.003702] br0: port 2(vnet0) entering learning state
[ 357.003704] br0: port 2(vnet0) entering learning state
[ 366.020017] br0: port 2(vnet0) entering forwarding state
[ 367.050024] vnet0: no IPv6 routers present l)idx08f5
1[20.298 aefas x0000000(
4[20.294 i:38 om d_ad0Nttitd263-0sre 4-bnu 15054]Cl rc: 15055] 15055] 15055] 15055] 15055] 15056] 1bfpo_re05/x0[ad0
4[20.292 [ffff81de> epo_re05/x0 15057] ycrqetwie03b040[ad0
4[20.290 [ffffa017> ad0+xe/x5 ri1] 15058] eal_pnlc_lg+x/x0 15058] 15059] 15059] 15059] 15059] 15059] enltra_epr0001
4[20.200 ialn okdbgigdet enltit_ x0000 H D hne
3[55.640 t4 Err eoCm ess HRyh 08 3[55.646 t40:fie omn:RA PM UUD 84088]aa.0 m 00:00:1d/40:90:04 a c 228i
3[55.644 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.643 t40:sau:{DD 3[55.647 t40:fie omn:RA PM UUD 84080]aa.0 m 00:80:dd/40:90:04 a c 228i
3[55.654 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.653 t40:sau:{DD 3[55.656 t40:fie omn:RA PM UUD 84082]aa.0 m 00:00:5d/40:90:04 a c 228i
3[55.653 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.652 t40:sau:{DD 3[55.656 t40:fie omn:RA PM UUD 84084]aa.0 m 00:80:9d/40:90:04 a c 228i
3[55.652 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.651 t40:sau:{DD 3[55.655 t40:fie omn:RA PM UUD 84086]aa.0 m 00:00:dd/40:90:04 a c 228i
3[55.651 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.650 t40:sau:{DD 3[55.654 t40:fie omn:RA PM UUD 84088]aa.0 m 00:80:1d/40:90:04 a c 228i
3[55.650 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.650 t40:sau:{DD 3[55.654 t40:fie omn:RA PM UUD 84089]aa.0 m 00:00:5d/40:90:04 a c 228i
3[55.660 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.668 t40:sau:{DD 3[55.662 t40:fie omn:RA PM UUD 84081]aa.0 m 00:80:9d/40:90:04 a c 228i
3[55.668 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.668 t40:sau:{DD 3[55.724 t40:fie omn:RA PM UUD:03:00/0tg8nq548 n 84008] e 00:c0:9d/00:90:04 ms x0(T u ro) 84010]aa.0 tts RY} 84029]aa.0 aldcmad EDFDAQEE
3[55.706 t40:cd6/04:01:a0:03:00/0tg9nq548 n 84034] e 00:c0:9d/00:90:04 ms x0(T u ro) 84049]aa.0 tts RY} 84048]aa.0 aldcmad EDFDAQEE
3[55.739 t40:cd6/05:01:a0:03:00/0tg1 c 228i
3[55.739 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.742 t40:sau:{DD 3[55.703 t40:fie omn:RA PM UUD 84074]aa.0 m 00:80:9d/40:90:04 a 1nq548 n 84074] e 00:c0:9d/00:90:04 ms x0(T u ro) 84083]aa.0 tts RY} 84098]aa.0 aldcmad EDFDAQEE
3[55.797 t40:cd6/06:01:a0:03:00/0tg1 c 228i
3[55.798 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.811 t40:sau:{DD 0 aldcmad EDFDAQEE
3[55.839 t40:cd6/06:0a:90:03:00/0tg1 c 228i
3[55.830 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.851 t40:sau:{DD 3[55.818 t40:fie omn:RA PM UUD 84048]aa.0 m 00:00:9d/40:90:04 a 4nq548 n 84048] e 00:c0:9d/00:90:04 ms x0(T u ro) 84058]aa.0 tts RY} 84064]aa.0 aldcmad EDFDAQEE
3[55.809 t40:cd6/07:0a:90:03:00/0tg1 c 228i
3[55.800 rs4/05:01:a0:03:00/0Eak01 AAbserr
3[55.826 t40:sau:{DD 3[55.871 t40:fie omn:RA PM UUD 84098]aa.0 m 00:00:1d/40:90:04 a 6nq548 n 84098] e 00:c0:9d/00:90:04 ms x0(T u ro) 84007]aa.0 tts RY}[ 5854.091012] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.091573] ata4.00: cmd 60/00:88:00:b5:d9/04:00:39:00:00/40 tag 17 ncq 524288 in
[ 5854.091574] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.092690] ata4.00: status: { DRDY }
[ 5854.093287] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.093817] ata4.00: cmd 60/00:90:00:b9:d9/04:00:39:00:00/40 tag 18 ncq 524288 in
[ 5854.093817] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.094964] ata4.00: status: { DRDY }
[ 5854.095510] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.096105] ata4.00: cmd 60/00:98:00:bd:d9/04:00:39:00:00/40 tag 19 ncq 524288 in
[ 5854.096105] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.097246] ata4.00: status: { DRDY }
[ 5854.097773] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.098338] ata4.00: cmd 60/00:a0:00:c1:d9/04:00:39:00:00/40 tag 20 ncq 524288 in
[ 5854.098339] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.099491] ata4.00: status: { DRDY }
[ 5854.100084] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.100658] ata4.00: cmd 60/00:a8:00:c5:d9/04:00:39:00:00/40 tag 21 ncq 524288 in
[ 5854.100659] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.101775] ata4.00: status: { DRDY }
[ 5854.102392] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.102924] ata4.00: cmd 60/00:b0:00:c9:d9/04:00:39:00:00/40 tag 22 ncq 524288 in
[ 5854.102925] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.104080] ata4.00: status: { DRDY }
[ 5854.104639] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.105206] ata4.00: cmd 60/00:b8:00:cd:d9/04:00:39:00:00/40 tag 23 ncq 524288 in
[ 5854.105207] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.106377] ata4.00: status: { DRDY }
[ 5854.106921] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.107493] ata4.00: cmd 60/00:c0:00:d1:d9/04:00:39:00:00/40 tag 24 ncq 524288 in
[ 5854.107493] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.108651] ata4.00: status: { DRDY }
[ 5854.109201] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.109784] ata4.00: cmd 60/00:c8:00:d5:d9/04:00:39:00:00/40 tag 25 ncq 524288 in
[ 5854.109785] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.110981] ata4.00: status: { DRDY }
[ 5854.111555] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.112111] ata4.00: cmd 60/00:d0:00:d9:d9/04:00:39:00:00/40 tag 26 ncq 524288 in
[ 5854.112111] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.113248] ata4.00: status: { DRDY }
[ 5854.113839] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.114408] ata4.00: cmd 60/00:d8:00:dd:d9/04:00:39:00:00/40 tag 27 ncq 524288 in
[ 5854.114409] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.115586] ata4.00: status: { DRDY }
[ 5854.116127] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.116691] ata4.00: cmd 60/00:e0:00:e1:d9/04:00:39:00:00/40 tag 28 ncq 524288 in
[ 5854.116691] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.117856] ata4.00: status: { DRDY }
[ 5854.118430] ata4.00: failed command: READ FPDMA QUEUED
[ 5854.119004] ata4.00: cmd 60/00:e8:00:e5:d9/04:00:39:00:00/40 tag 29 ncq 524288 in
[ 5854.119005] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
[ 5854.120213] ata4.00: status: { DRDY }
[ 5855.100038] ata4: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
[ 5855.104300] ata4.00: configured for UDMA/133
[ 5855.104351] ata4: EH complete
[10013.907683] general protection fault: 0000 [#1] SMP [10013.907997] last sysfs file: /sys/devices/system/cpu/cpu5/cache/index2/shared_cpu_map
[10013.908574] CPU 0 [10013.908577] Modules linked in: ip6table_filter ip6_tables ipt_MASQUERADE iptable_nat nf_nat nf_conntrack_ipv4 nf_defrag_ipv4 xt_state nf_conntrack ipt_REJECT xt_CHECKSUM iptable_mangle xt_tcpudp iptable_filter ip_tables x_tables kvm_amd kvm eeepc_wmi sparse_keymap bridge stp nouveau sp5100_tco ttm i2c_piix4 edac_core edac_mce_amd drm_kms_helper k10temp drm i2c_algo_bit video lp parport raid10 raid456 async_pq async_xor xor async_memcpy async_raid6_recov usb_storage uas r8169 xhci_hcd ahci libahci raid6_pq async_tx raid1 raid0 multipath linear
[10013.911080] [10013.911734] Pid: 349, comm: md0_resync Tainted: G B 2.6.38-10-server #46-Ubuntu To be filled by O.E.M. To be filled by O.E.M./SABERTOOTH 990FX
[10013.912418] RIP: 0010:[] [] kmem_cache_alloc+0x58/0x110
[10013.913102] RSP: 0018:ffff88041b6079c0 EFLAGS: 00010006
[10013.913783] RAX: 0000000000000000 RBX: ffff88043f802600 RCX: ffffffff813df60a
[10013.914472] RDX: 0000000000000000 RSI: 0000000000000020 RDI: ffff88043f802600
[10013.915159] RBP: ffff88041b607a00 R08: ffff8800bd416a80 R09: ffff880414db0500
[10013.915839] R10: 00000000684eb800 R11: 0000000000000001 R12: 0200000000000000
[10013.916523] R13: 0000000000000086 R14: 0000000000000020 R15: ffff88041b42b400
[10013.917204] FS: 00007f741ce31700(0000) GS:ffff8800bd400000(0000) knlGS:0000000000000000
[10013.917529] CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b
[10013.917529] CR2: 00007f4402d5dd00 CR3: 00000004108a5000 CR4: 00000000000006f0
[10013.917529] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[10013.917529] DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400
[10013.917529] Process md0_resync (pid: 349, threadinfo ffff88041b606000, task ffff88041b945b80)
[10013.917529] Stack:
[10013.917529] ffff88041b6079e0 000000201b6079e0 0000000000000082 ffffffff81a77fa0
[10013.917529] ffff880414db0500 0000000000000020 0000000000000020 ffff88041b42b400
[10013.917529] ffff88041b607a30 ffffffff813df60a ffff880400000000 ffff88041be74020
[10013.917529] Call Trace:
[10013.917529] [] scsi_pool_alloc_command+0x4a/0x80
[10013.917529] [] scsi_host_alloc_command.clone.7+0x33/0xa0
[10013.159 [ffff83ff> _cigtcmad02/x0103972] cistpf_md08/x0103972] 103972] 103972] 103972] _eei_nlgdvc+x704
4[01.159 [ffff822c> eei_nlgdvc+x005
4[01.159 [ffff82c9> l_nlg02/x0103972] ad0upu+xd03 ri1]103972] dupu+x204
4[01.159 [ffff8421> dd_yc08d0c0103972] [10013.917529] [] ? _raw_spin_lock+0xe/0x20
[10013.917529] [] ? recalc_sigpending+0x1/x0103972] 103972] 103972] 103972] 103972] enltra_epr0001
0[01.159 oe 66 06 04 9c a6 69 66 04 b0 54 30 5a c0 04 b2 d8 40 4a 00 04 34 8103972]RP 103972] S ff80167c>103972]– n rc 5355716c]-
This is the output from syslog:
Jul 29 21:23:09 Othelo kernel: [ 5854.068449] ata4.00: exception Emask 0x10 SAct 0x7fffffff SErr 0x90202 action 0xe frozen
Jul 29 21:23:09 Othelo kernel: [ 5854.068464] ata4.00: irqstat00400,PYRYcagd 84087]aa:Sro:{RcvomPritPYdCg1BB} 84087]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.643 t40:cd6/00:0f:90:03:00/0tg0nq548 n 84088] e 00:c0:9d/00:90:04 ms x0(T u ro) 84089]aa.0 tts RY} 84089]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.653 t40:cd6/00:0e:90:03:00/0tg1nq548 n 84080] e 00:c0:9d/00:90:04 ms x0(T u ro) 84081]aa.0 tts RY} 84081]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.652 t40:cd6/01:0f:90:03:00/0tg2nq548 n 84082] e 00:c0:9d/00:90:04 ms x0(T u ro) 84083]aa.0 tts RY} 84083]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.652 t40:cd6/01:0f:90:03:00/0tg3nq548 n 84084] e 00:c0:9d/00:90:04 ms x0(T u ro) 84085]aa.0 tts RY} 84085]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.651 t40:cd6/02:0f:90:03:00/0tg4nq548 n 84086] e 00:c0:9d/00:90:04 ms x0(T u ro) 84087]aa.0 tts RY} 84087]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.650 t40:cd6/02:00:a0:03:00/0tg5nq548 n 84088] e 00:c0:9d/00:90:04 ms x0(T u ro) 84089]aa.0 tts RY} 84089]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.659 t40:cd6/03:00:a0:03:00/0tg6nq548 n 84080] e 00:c0:9d/00:90:04 ms x0(T u ro) 84080]aa.0 tts RY} 84081]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.667 t40:cd6/03:00:a0:03:00/0tg7nq548 n 84081] e 00:c0:9d/00:90:04 ms x0(T u ro) 84099]aa.0 tts RY} 84007]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: [ 5854.070785] ata4.00: cmd 60/00:40:00:0d:da/040:90:04 a c 228i
Jul 29 21:23:09 Othelo kernel: 3[55.776 rs4/05:01:a0:03:00/0Eak01 AAbserr
Jul 29 21:23:09 Othelo kernel: 3[55.797 t40:sau:{DD Jul 29 21:23:09 Othelo kernel: 3[55.743 t40:fie omn:RA PM UUD 84034]aa.0 m 00:80:1d/40:90:04 a c 228i
Jul 29 21:23:09 Othelo kernel: 3[55.707 rs4/05:01:a0:03:00/0Eak01 AAbserr
Jul 29 21:23:09 Othelo kernel: 3[55.710 t40:sau:{DD Jul 29 21:23:09 Othelo kernel: 3[55.777 t40:fie omn:RA PM UUD 84052]aa.0 m 00:00:5d/40:90:04 a 0nq548 n 84052] e 00:c0:9d/00:90:04 ms x0(T u ro) 84069]aa.0 tts RY} 84075]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.763 t40:cd6/05:01:a0:03:00/0tg1 c 228i
Jul 29 21:23:09 Othelo kernel: 3[55.763 rs4/05:01:a0:03:00/0Eak01 AAbserr
Jul 29 21:23:09 Othelo kernel: 3[55.784 t40:sau:{DD Jul 29 21:23:09 Othelo kernel: 3[55.737 t40:fie omn:RA PM UUD 84096]aa.0 m 00:00:dd/40:90:04 a 2nq548 n 84096] e 00:c0:9d/00:90:04 ms x0(T u ro) 84018]aa.0 tts RY}[ 5854.081762] ata4.0:fie omn:RA PM UUD 84021]aa.0 m 00:80:5d/40:90:04 a 3nq548 n 84022] e 00:c0:9d/00:90:04 ms x0(T u ro) 84032]aa.0 tts RY} 84045]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.867 t40:cd6/07:0a:90:03:00/0tg1 c 228i
Jul 29 21:23:09 Othelo kernel: 3[55.868 rs4/05:01:a0:03:00/0Eak01 AAbserr
Jul 29 21:23:09 Othelo kernel: 3[55.881 t40:sau:{DD Jul 29 21:23:09 Othelo kernel: 3[55.849 t40:fie omn:RA PM UUD 84073]aa.0 m 00:80:dd/40:90:04 a 5nq548 n 84074] e 00:c0:9d/00:90:04 ms x0(T u ro) 84082]aa.0 tts RY} 84083]aa.0 aldcmad EDFDAQEE
Jul 29 21:23:09 Othelo kernel: 3[55.822 t40:cd6/08:0b:90:03:00/0tg1 c 228i
Jul 29 21:23:09 Othelo kernel: 3[55.823 rs4/05:01:a0:03:00/0Eak01 AAbserr
Jul 29 21:23:09 Othelo kernel: 3[55.943 t40:sau:{DD Jul 29 21:23:09 Othelo kernel: [ 5854.120747] ata4.00: failed command: READ FPDMA QUEUED
Jul 29 21:23:09 Othelo kernel: [ 5854.121321] ata4.00: cmd 60/00:f0:00:e9:d9/04:00:39:00:00/40 tag 30 ncq 524288 in
Jul 29 21:23:09 Othelo kernel: [ 5854.121322] res 40/00:5c:00:19:da/00:00:39:00:00/40 Emask 0x10 (ATA bus error)
Jul 29 21:23:09 Othelo kernel: [ 5854.122483] ata4.00: status: { DRDY }
Jul 29 21:23:09 Othelo kernel: [ 5854.123050] ata4: hard resetting link
Jul 29 21:42:45 Othelo mdadm[1563]: Rebuild62 event detected on md device /dev/md/0
Jul 29 22:16:06 Othelo mdadm[1563]: Rebuild81 event detected on md device /dev/md/0
Jul 29 22:17:01 Othelo CRON[13235]: (root) CMD ( cd / && run-parts –report /etc/cron.hourly)
Jul 29 22:32:29 Othelo kernel: 4972] cigtcmad04/x0103972] dpe_n0a/xa
Jul 29 22:32:29 Othelo kernel: 4[01.159 [ffff821b> ediemv_eus+x80a
Jul 29 22:32:29 Othelo kernel: 4[01.159 [ffff8222> l_ekrqet0c/x1
Jul 29 22:32:29 Othelo kernel: 4[01.159 [ffff837c> cirqetf+x6040103972] tra+x60a
Jul 29 22:32:29 Othelo kernel: 4[01.159 [ffff80ce> enltra_epr0401
Jul 29 22:32:29 Othelo kernel: 4[01.159 [ffff807e> tra+x/x0103972] 8 40 98 04 9e 79 66 06 04 5e 5
Jul 29 22:32:29 Othelo kernel: 1[01.159 I [ffff815e> mmccealc05/x1
Jul 29 22:32:29 Othelo kernel: 4[01.159 RP
Источник: https://serverfault.com/a/295746
hetzner.de проблемы с жесткими дисками
В связи с очередным сбоем на хетснеровских серверах раскопал и вернул черновик в строй. Сегодня в выходной меня разбудили и сообщили, что сервер, расположенный у любимого мною хостера совсем молчит и что это не есть хорошо, поскольку он не партизан в плену, а боевой сервер.
Краткое расследование показало проблемы с /dev/sda
=============================================================
Feb 3 11:50:36 hz kernel: ata1.00: exception Emask 0x0 SAct 0x1c SErr 0x0 action 0x0
Feb 3 11:50:36 hz kernel: ata1.00: irq_stat 0x40000008
Feb 3 11:50:36 hz kernel: ata1.00: failed command: READ FPDMA QUEUED
Feb 3 11:50:36 hz kernel: ata1.00: cmd 60/f8:10:a8:2c:18/00:00:a8:00:00/40 tag 2 ncq 126976 in
Feb 3 11:50:36 hz kernel: res 41/40:f8:98:2d:18/00:00:a8:00:00/00 Emask 0x409 (media error)<\p>
Feb 3 11:50:36 hz kernel: ata1.00: status: { DRDY ERR }
Feb 3 11:50:36 hz kernel: ata1.00: error: { UNC }
Feb 3 11:50:37 hz kernel: ata1.00: configured for UDMA/133
Feb 3 11:50:37 hz kernel: ata1: EH complete
Feb 3 11:50:41 hz kernel: ata1.00: exception Emask 0x0 SAct 0x4 SErr 0x0 action 0x0
Feb 3 11:50:41 hz kernel: ata1.00: irq_stat 0x40000008
Feb 3 11:50:41 hz kernel: ata1.00: failed command: READ FPDMA QUEUED
Feb 3 11:50:41 hz kernel: ata1.00: cmd 60/f8:10:a8:2c:18/00:00:a8:00:00/40 tag 2 ncq 126976 in
Feb 3 11:50:41 hz kernel: res 41/40:f8:98:2d:18/00:00:a8:00:00/00 Emask 0x409 (media error)<\p>
Feb 3 11:50:41 hz kernel: ata1.00: status: { DRDY ERR }
Feb 3 11:50:41 hz kernel: ata1.00: error: { UNC }
Feb 3 11:50:41 hz kernel: ata1.00: configured for UDMA/133
Feb 3 11:50:41 hz kernel: ata1: EH complete
=============================================================
# hdparm -t /dev/sda
/dev/sda:
Timing buffered disk reads: 28 MB in 3.07 seconds = 9.13 MB/sec
=============================================================
cat /proc/mdadm сообщал, что он в курсе происходившего и ведет проверку (recheck) массивов, на что просит не много не мало а полтора года (размер дисков по 3Tb). А все виртуальные машины на сервере начали вести себя очень плавно и неспеша. Я естественно расстроился такому повороту событий, поскольку за полтора года меня четвертуют, колесуют и на кол посадят за тормозящие корп сайты. Гугл вселил в меня надежду, что проблема моя далеко не нова и что помочь ей можно сменив шлейф, винт ну или на крайняк контроллер – это кому уж как повезет.
Не мудрствуя лукаво я заполнил форму на robot.your-server.de в разделе requests. Где в наиболее подходящем из шаблонов ( requests – Dedicated and Virtual Server requests…
– Server problems – Hard drive is broken) мне предлагалось описать с каким из винтов у меня проблемы, указать серийный номер и привести кусок логов, который поверг меня в наибольший восторг.
Именно это я и сделал, не забыв указать в примечаниях, что я не уверен в настройках BIOS и тому как сервер отнесется к смене загрузочного диска.
Примерно через пол часа я получил ответ с просьбой выслать вывод от smartctl –all /dev/sda и советом почитать статьи из их базы знаний
Первое я незамедлительно выслал, а сам тем временем начал сверять свои действия с инструкцией и убедившись, что все выполнил правильно, так же рапортовал об этом саппорту.
Саппорт как оказалось тоже умеет гуглить и умеет считать свои денежки, видимо поэтому они первым делом предложили мне не горячиться, а попробовать начать с замены шлейфа. Я незамедлительно согласился, дав так-же свое согласие на кратковременное отключение сервера для совершения сего действа.
Спустя пол часа отсутствия сервера в сети я забил тревогу и написал в саппорт, что что-то видимо пошло не так, поскольку сервер по прежнему на запросы не отвечает и в сети не виден как мне, так и сайту управления хостингом.
Ответ меня несколько удивил и порадовал – мне дали шанс увидеть консоль своего сервака.
=============================================================
Dear Client.
We have connected a remote console (LARA) to your server for check this.
Access details:
Username: **
Password: ***
More information can be found in our wiki:
=============================================================
Правда радость моя не была долгой, Error:Authentication failed. обломил мои ожидания. Зато пока я тыкался в ЛАРУ коварные саппортеры успели таки ребутнуть и поправить загрузку сервака (а может просто забыли включить)) или холодный старт сервера у них занимает более получаса – ну там с каким нибудь аппаратным тестированием памяти/вентиляторов/еще чего полезного).
Однако факт, что я получил обратно свой сервак с заработавшими винтами
=============================================================
# hdparm -tT /dev/sda
/dev/sda:
Timing cached reads: 27346 MB in 2.00 seconds = 13688.79 MB/sec
Timing buffered disk reads: 510 MB in 3.01 seconds = 169.66 MB/sec
=============================================================
И настала пора возвращать разделы в RAID из которого, как оказалось, я зря их вывел. Вот только автоматическое определение дисков не дало мне и тут поскучать и оставшиеся бесхозными разделы были определены как новые RAID массивы
=============================================================
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md125 : active (auto-read-only) raid1 sda1[0]
33553336 blocks super 1.2 [2/1] [U_]
md126 : active (auto-read-only) raid1 sda2[0]
524276 blocks super 1.2 [2/1] [U_]
md127 : active raid1 sda3[0]
2896184639 blocks super 1.2 [2/1] [U_]
md2 : active raid1 sdb3[1]
2896184639 blocks super 1.2 [2/1] [_U]
md1 : active (auto-read-only) raid1 sdb2[1]
524276 blocks super 1.2 [2/1] [_U]
md0 : active (auto-read-only) raid1 sdb1[1]
33553336 blocks super 1.2 [2/1] [_U]
unused devices:<\p>
=============================================================
Но тут уже было все просто и первые два раздела были добавлены за пару минут:
=============================================================
# mdadm –manage /dev/md0 –add /dev/sda1
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md126 : active (auto-read-only) raid1 sda2[0]
524276 blocks super 1.2 [2/1] [U_]
md127 : active raid1 sda3[0]
2896184639 blocks super 1.2 [2/1] [U_]
md2 : active raid1 sdb3[1]
2896184639 blocks super 1.2 [2/1] [_U]
md1 : active (auto-read-only) raid1 sdb2[1]
524276 blocks super 1.2 [2/1] [_U]
md0 : active raid1 sda1[2] sdb1[1]
33553336 blocks super 1.2 [2/1] [_U]
[>………………..] recovery = 2.4% (812160/33553336) finish=6.0min speed=90240K/sec
=============================================================
А вот повторив операцию с последним я напоролся на ошибочку
=============================================================
# mdadm -S /dev/md127
mdadm: failed to stop array /dev/md127: Device or resource busy
Perhaps a running process, mounted filesystem or active volume group?
# vgscan
Reading all physical volumes. This may take a while…
Found duplicate PV RrnPfgBunCs217VgnxsZifyY9Lxw42Jx: using /dev/md127 not /dev/md2
Found volume group “vg0” using metadata type lvm2
=============================================================
самым простым мне показалось поправить /etc/lvm/lvm.conf и перегрузиться
=============================================================
filter = [ “a|^/dev/md2$|”, “r/.*/” ]
=============================================================
# reboot
…
# vgscan
Reading all physical volumes. This may take a while…
Found volume group “vg0” using metadata type lvm2
# pvdisplay
— Physical volume —
PV Name /dev/md2
VG Name vg0
PV Size 2.70 TiB / not usable 1.31 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 707076
Free PE 367876
Allocated PE 339200
PV UUID RrnPfg-BunC-s217-Vgnx-sZif-yY9L-xw42Jx
# mdadm -S /dev/md127
# mdadm –manage /dev/md2 –add /dev/sda3
mdadm: added /dev/sda3
# cat /proc/mdstat
Personalities : [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md2 : active raid1 sda3[2] sdb3[1]
2896184639 blocks super 1.2 [2/1] [_U]
[>………………..] recovery = 0.0% (2571392/2896184639) finish=731.4min speed=65933K/sec
md1 : active raid1 sda2[2] sdb2[1]
524276 blocks super 1.2 [2/2] [UU]
md0 : active (auto-read-only) raid1 sda1[2] sdb1[1]
33553336 blocks super 1.2 [2/2] [UU]
unused devices:<\p>
=============================================================
Осталось поправить обратно /etc/lvm/lvm.conf, дождаться пока соберется массив и ребутнуться для проверки.
Источник: http://admway.bystrov.net/2013/02/hetznerde.html
failed command: READ FPDMA QUEUED FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
So my last Seagate SATA drive in my RAID 6 Array died spectacularly taking out my 4.8.4 Kernel and locking up my storage to the point where the only way I can get to it is via the kernel boot parameter init=/bin/bash . The disk lasted about 5.762 years:
[root@rfc1178-01 log]# smartctl -A /dev/sdd smartctl 6.1 2013-03-16 r3800 [i686-linux-3.10.5-201.fc19.i686] (local build)
Copyright (C) 2002-13, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 082 082 006 Pre-fail Always – 49816764 3 Spin_Up_Time 0×0003 095 095 000 Pre-fail Always – 0 4 Start_Stop_Count 0×0032 100 100 020 Old_age Always – 358 5 Reallocated_Sector_Ct 0×0033 100 100 036 Pre-fail Always – 0 7 Seek_Error_Rate 0x000f 082 060 030 Pre-fail Always – 199979728 9 Power_On_Hours 0×0032 043 043 000 Old_age Always – 50479 10 Spin_Retry_Count 0×0013 100 100 097 Pre-fail Always – 0 12 Power_Cycle_Count 0×0032 100 100 020 Old_age Always – 173 183 Runtime_Bad_Block 0×0032 100 100 000 Old_age Always – 0 184 End-to-End_Error 0×0032 100 100 099 Old_age Always – 0 187 Reported_Uncorrect 0×0032 001 001 000 Old_age Always – 665 188 Command_Timeout 0×0032 099 099 000 Old_age Always – 65540 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always – 0 190 Airflow_Temperature_Cel 0×0022 069 059 045 Old_age Always – 31 (Min/Max 23/31) 194 Temperature_Celsius 0×0022 031 041 000 Old_age Always – 31 (0 20 0 0 0) 195 Hardware_ECC_Recovered 0x001a 039 018 000 Old_age Always – 49816764 197 Current_Pending_Sector 0×0012 099 098 000 Old_age Always – 42 198 Offline_Uncorrectable 0×0010 099 098 000 Old_age Offline – 42 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always – 0 240 Head_Flying_Hours 0×0000 100 253 000 Old_age Offline – 266288022969 241 Total_LBAs_Written 0×0000 100 253 000 Old_age Offline – 1037691197
242 Total_LBAs_Read 0×0000 100 253 000 Old_age Offline – 1219786117
[root@rfc1178-01 log]# hdparm -i /dev/sdd
/dev/sdd:
Model=ST31000520AS, FwRev=CC32, SerialNo=9VX0WJKA Config={ HardSect NotMFM HdSw>15uSec Fixed DTR>10Mbs RotSpdTol>.5% } RawCHS=16383/16/63, TrkSize=0, SectSize=0, ECCbytes=4 BuffType=unknown, BuffSize=unknown, MaxMultSect=16, MultSect=off CurCHS=16383/16/63, CurSects=16514064, LBA=yes, LBAsects=1953525168 IORDY=on/off, tPIO={min:120,w/IORDY:120}, tDMA={min:120,rec:120} PIO modes: pio0 pio1 pio2 pio3 pio4 DMA modes: mdma0 mdma1 mdma2 UDMA modes: udma0 udma1 udma2 udma3 udma4 udma5 *udma6 AdvancedPM=yes: unknown setting WriteCache=enabled
Drive conforms to: unknown: ATA/ATAPI-4,5,6,7
* signifies the current active mode
[root@rfc1178-01 log]# [root@rfc1178-01 log]#
[root@rfc1178-01 log]# fdisk -l /dev/sdd
Disk /dev/sdd: 1000.2 GB, 1000204886016 bytes, 1953525168 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
[root@rfc1178-01 log]#
And with these errors in the /var/log/messages ( /root/spectacular-failure-messages ):
Mar 19 15:49:09 mbpc-pc kernel: ata4.00: exception Emask 0×0 SAct 0x7fffffff SErr 0×0 action 0×0 Mar 19 15:49:09 mbpc-pc kernel: ata4.00: irq_stat 0×40000008 Mar 19 15:49:09 mbpc-pc kernel: ata4.00: failed command: READ FPDMA QUEUED Mar 19 15:49:09 mbpc-pc kernel: ata4.00: cmd 60/40:70:40:2b:b2/05:00:3b:00:00/40 tag 14 ncq dma 688128 in Mar 19 15:49:09 mbpc-pc kernel: res 41/40:40:ff:2b:b2/00:05:3b:00:00/00 Emask 0×409 (media error) Mar 19 15:49:09 mbpc-pc kernel: ata4.00: status: { DRDY ERR } Mar 19 15:49:09 mbpc-pc kernel: ata4.00: error: { UNC } Mar 19 15:49:09 mbpc-pc kernel: qla2xxx [0000:04:00.0]-680a:20: Loop down – seconds remaining 160. Mar 19 15:49:09 mbpc-pc kernel: ata4.00: configured for UDMA/133 Mar 19 15:49:09 mbpc-pc kernel: sd 7:0:0:0: [sdd] tag#14 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE Mar 19 15:49:09 mbpc-pc kernel: sd 7:0:0:0: [sdd] tag#14 Sense Key : Medium Error [current] Mar 19 15:49:09 mbpc-pc kernel: sd 7:0:0:0: [sdd] tag#14 Add. Sense: Unrecovered read error – auto reallocate failed Mar 19 15:49:09 mbpc-pc kernel: sd 7:0:0:0: [sdd] tag#14 CDB: Read(10) 28 00 3b b2 2b 40 00 05 40 00 Mar 19 15:49:09 mbpc-pc kernel: blk_update_request: I/O error, dev sdd, sector 1001532415
Mar 19 15:49:09 mbpc-pc kernel: ata4: EH complete
And with these following:
Mar 19 15:54:20 mbpc-pc kernel: blk_update_request: I/O error, dev sdd, sector 1001534264 Mar 19 15:54:20 mbpc-pc kernel: ata4: EH complete Mar 19 15:54:24 mbpc-pc kernel: ata4.00: exception Emask 0×0 SAct 0x7fffffff SErr 0×0 action 0×0 Mar 19 15:54:24 mbpc-pc kernel: ata4.00: irq_stat 0×40000008 Mar 19 15:54:24 mbpc-pc kernel: ata4.00: failed command: READ FPDMA QUEUED Mar 19 15:54:24 mbpc-pc kernel: ata4.00: cmd 60/08:28:48:34:b2/00:00:3b:00:00/40 tag 5 ncq dma 4096 in Mar 19 15:54:24 mbpc-pc kernel: res 41/40:08:48:34:b2/00:00:3b:00:00/00 Emask 0×409 (media error) Mar 19 15:54:24 mbpc-pc kernel: ata4.00: status: { DRDY ERR } Mar 19 15:54:24 mbpc-pc kernel: ata4.00: error: { UNC } Mar 19 15:54:24 mbpc-pc kernel: ata4.00: configured for UDMA/133 Mar 19 15:54:24 mbpc-pc kernel: sd 7:0:0:0: [sdd] tag#5 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE Mar 19 15:54:24 mbpc-pc kernel: sd 7:0:0:0: [sdd] tag#5 Sense Key : Medium Error [current] Mar 19 15:54:24 mbpc-pc kernel: sd 7:0:0:0: [sdd] tag#5 Add. Sense: Unrecovered read error – auto reallocate failed Mar 19 15:54:24 mbpc-pc kernel: sd 7:0:0:0: [sdd] tag#5 CDB: Read(10) 28 00 3b b2 34 48 00 00 08 00 Mar 19 15:54:24 mbpc-pc kernel: blk_update_request: I/O error, dev sdd, sector 1001534536 Mar 19 15:54:24 mbpc-pc kernel: ata4: EH complete Mar 19 15:54:24 mbpc-pc kernel: qla2xxx [0000:04:00.0]-e872:20: qlt_24xx_atio_pkt_all_vps: qla_target(0): type d ox_id 0000 Mar 19 15:54:24 mbpc-pc kernel: qla2xxx [0000:04:00.0]-e82e:20: IMMED_NOTIFY ATIO Mar 19 15:54:24 mbpc-pc kernel: qla2xxx [0000:04:00.0]-f826:20: qla_target(0): Port ID: 0×00:00:01 ELS opcode: 0×03 Mar 19 15:54:24 mbpc-pc kernel: qla2xxx [0000:04:00.0]-e81c:20: Sending TERM ELS CTIO (ha=ffff88010ef90000) Mar 19 15:54:24 mbpc-pc kernel: qla2xxx [0000:04:00.0]-f897:20: Linking sess ffff8800c3f84b40 [0] wwn 50:01:43:80:16:77:99:38 with PLOGI ACK to wwn 50:01:43:80:16:77:99:38 s_id 01:00:00, ref=1 Mar 19 15:54:24 mbpc-pc kernel: qla2xxx [0000:04:00.0]-e862:20: qla_target(0): Unexpected NOTIFY_ACK received Mar 19 15:54:26 mbpc-pc kernel: INFO: task kworker/1:2:96 blocked for more than 120 seconds. Mar 19 15:54:26 mbpc-pc kernel: Not tainted 4.8.4 #2 Mar 19 15:54:26 mbpc-pc kernel: “echo 0 > /proc/sys/kernel/hung_task_timeout_secs” disables this message. Mar 19 15:54:26 mbpc-pc kernel: kworker/1:2 D ffff8801115db718 0 96 2 0×0000000 Mar 19 15:54:26 mbpc-pc kernel: kworker/1:2 D ffff8801115db718 0 96 2 0×00000000 Mar 19 15:54:26 mbpc-pc kernel: Workqueue: qla_tgt_wq qlt_do_work [qla2xxx] Mar 19 15:54:26 mbpc-pc kernel: ffff8801115db718 ffff8801115db688 ffff88011a83a300 ffff88011fc17a80 Mar 19 15:54:26 mbpc-pc kernel: ffff8801115d20c0 ffff880100000001 ffffffff8109075d 0000000000000000 Mar 19 15:54:26 mbpc-pc kernel: ffff88011ffdc5c0 ffff880100000000 0000000000000011 ffff880100000000 Mar 19 15:54:26 mbpc-pc kernel: Call Trace:
Mar 19 15:54:26 mbpc-pc kernel: [
…..
So with that goes the last disk of it's kind in this array with NO data loss to the array itself, over the last 8 years.
Cheers,
TK
Источник: http://microdevsys.com/wp/failed-command-read-fpdma-queued-failed-result-hostbytedid_ok-driverbytedriver_sense/
Как не надо восстанавливать данные, или чтобы вам тоже так везло
Все мы периодически сталкиваемся с отказами устройств хранения. В интернете написаны сотни инструкций, как без специального оборудования прочитать все что только возможно с устройств, еще отвечающих на обычные запросы ОС.
Но мне долгие годы не везло, диски либо умирали совсем-совсем, либо файловая система была еще доступна и я просто читал все то, что читалось в обычном режиме. И ждал. Должно же было случиться, чтобы умирающий диск попал мне именно в состоянии, требующем большего, чем самые элементарные действия?
И вот этот день настал.
На разделе поверх софтового raid0, хранившем, откровенно говоря, всякую ерунду, файлы оказались недоступны, а причина — долгожданный I/O Error. Неожиданным было то, что устройства-носителя второй половинки рэйда вообще не оказалось в выводе fdisk, хотя список файлов был доступен.
Перезагрузка — и массив собрался, а файлы прекрасно читаются. В отчете SMART видно огромное количество переназначенных секторов. Как раз то, что нужно. Отключаю диски и начинаю продумывать стратегию восстановления.
Для вычитывания уцелевших секторов решено было использовать GNU ddrescue — специализированную версию dd для чтения данных с умирающих дисков, которая позволяет выбирать стратегию чтения и умеет строить карту диска для продолжения работы после сбоев, а они обязательно будут, работаю ведь с неисправными устройством.
Итак, подключаю первый диск к своему десктопу, и POST торжественно сообщает, что один из подключенных дисков совсем плох. Загрузка ОС прошла штатно, если не считать пару сообщений о каких-то ошибках ata устройства. После успешной загрузки fdisk -l пациента видит, ну наконец-то я буду восстанавливать целостность данных raid0.
ddrescue -ndAvv /dev/sdd1 bad mapbad
Процесс пошел довольно резво, 80 МБ/с. Из-за шума охлаждающего диски вентилятора, изъятого специально по такому случаю из списанного сервера, леденящих кровь звуков чтения умирающего диска было бы не слышно, даже если бы они были. Возможно, не слышать их даже лучше. Меньше знаешь — крепче спишь.
К утру работа ddrescue завершилась, и на новеньком диске лежали образ и карта погибающего товарища. Но повторный запуск ddrescue почему-то завершался подозрительно быстро, а карта
стала такой.# Rescue Logfile. Created by GNU ddrescue version 1.19 # Command line: ddrescue -ndAvv /dev/sdd1 bad mapbad # Start time: 2016-02-12 09:05:07 # Current time: 2016-02-12 09:06:45 # Finished # current_pos current_status 0xAA7A800000 + # pos size status 0x00000000 0xA6FF000000 + 0xA6FF000000 0x00810000 – 0xA6FF810000 0x0D7F0000 + 0xA70D000000 0x00810000 – 0xA70D810000 0x2887F0000 + 0xA996000000 0x01020000 – 0xA997020000 0x147E0000 + 0xA9AB800000 0x00810000 – 0xA9AC010000 0x4D7F0000 + 0xA9F9800000 0x00810000 – 0xA9FA010000 0x7AFF0000 + 0xAA75000000 0x01840000 – 0xAA76840000 0x03FC0000 + 0xAA7A800000 0x42E258400 –
«Что-то очевидно пошло не так», — подсказал сонный внутренний голос. «А попробуй-ка fdisk -l» — вот, и разум уже подключился. /dev/sdd в выводе не оказалось. — Как такое вообще возможно?, — Ах да, на сервере было тоже самое, — Значит, не все еще пропало: примерно такие мысли обитали в голове весь рабочий день.
Вечером подопытный диск опять подавал признаки жизни, а передо мной стояла непростая задача: что делать с полученным образом, ведь ddrescue c финализированной картой что-либо читать отказывался, оставив мне файл образа меньше размера раздела.
С одной стороны, ddrescue умеет заполнять – блоки произвольными данными, чтобы потом определить битые файлы. С другой стороны, я не просил его делать спарс-файл (параметр -S), и усиленное гугление вопроса о том, как именно будет заполняться меньший-чем-раздел файл образа, осталось без ответа.Что сделать, чтобы так не переживатьНа самом деле нужно было внимательно прочитать инструкцию и найти в ней параметр -p, который резервирует место на диске перед созданием обычного файла.
Полагаться на случай крайне не хотелось, и я решил с калькулятором в руках изучить карту диска. Оказалось, что 96% содержимого диска успешно прочиталось и попало в первый + блок. Но к сожалению, сумма всех + блоков не давала размер считанного образа, что окончательно спутало мне все карты. По-этому я пошел другим путем: раз у меня есть хорошее начало и черт знает что в конце, почему бы не достать старый добрый dd и не слепить из непонятного образа как раз то, с чем можно спокойно работать?dd if=bad of=bad_new bs=16M count=42751
dd if=/dev/zero of=bad_new bs=1024 seek=700432384 count=32139617
Результат — новенький образ, который теперь в точности такого же размера, как и умирающий раздел, а именно 750153729024 байт. Теперь займемся ноликами в конце. Делаю вручнуютакую карту# Rescue Logfile. Created by GNU ddrescue version 1.19 # Command line: ddrescue -ndAvv /dev/sdd1 bad mapbad # Start time: 2016-02-12 09:05:07 # Current time: 2016-02-12 09:06:45 # Finished # current_pos current_status 0xA6FF810000 ? # pos size status 0x00000000 0xA6FF000000 + 0xA6FF000000 0x00810000 – 0xA6FF810000 0x0D7F0000 ? 0xA70D000000 0x00810000 – 0xA70D810000 0x2887F0000 ? 0xA996000000 0x01020000 – 0xA997020000 0x147E0000 ? 0xA9AB800000 0x00810000 – 0xA9AC010000 0x4D7F0000 ? 0xA9F9800000 0x00810000 – 0xA9FA010000 0x7AFF0000 ? 0xAA75000000 0x01840000 – 0xAA76840000 0x03FC0000 ? 0xAA7A800000 0x42E258400 –
и запускаю:ddrescue -ndAvv /dev/sdd1 bad_new mapbad
Ура! Теперь все хорошо. Читающиеся блоки с диска переехали на пустое место нового образа по нужным адресам, а карта опять финализировалась, и мои приключения подходят к концу. Но может быть сделать последний рывок и перечитать – блоки по одному сектору? Теперь даю ddrescue
такую карту# Rescue Logfile. Created by GNU ddrescue version 1.19 # Command line: ddrescue -ndAvv /dev/sdd1 bad mapbad # Start time: 2016-02-12 09:05:07 # Current time: 2016-02-12 09:06:45 # Finished # current_pos current_status 0xA6FF000000 ? # pos size status 0x00000000 0xA6FF000000 + 0xA6FF000000 0x00810000 ? 0xA6FF810000 0x0D7F0000 + 0xA70D000000 0x00810000 ? 0xA70D810000 0x2887F0000 + 0xA996000000 0x01020000 ? 0xA997020000 0x147E0000 + 0xA9AB800000 0x00810000 ? 0xA9AC010000 0x4D7F0000 + 0xA9F9800000 0x00810000 ? 0xA9FA010000 0x7AFF0000 + 0xAA75000000 0x01840000 ? 0xAA76840000 0x03FC0000 + 0xAA7A800000 0x42E258400 ?
и запускаю так:ddrescue -ndAvv /dev/sdd1 -с1 bad_new mapbad
В общем, он повел себя совсем не так, как я рассчитывал. Наткнувшись на плохой сектор в – блоке, он переходил к следующему – блоку, пока не зацепился за уверенное чтение из последнего – блока. Час спустя я остановил это безобразие с помощью CTRL-C и запустил чтение на нормальной скорости. Еще несколько гигабайт из конца раздела прочитались, пока ddrescue снова не напоролся на сбойные сектора, что почему-то опять привело к пропаданию /dev/sdd из системы и финализации карты, которая сильно распухла и представляла собой месиво из +, – и ? блоков. Разбирать все это не было уже никакого смысла, и я решил прекратить мучить умирающего и заняться, наконец, сборкой массива. Но перед этим захотелось выяснить, что было бы, если бы я использовал режим заполнения. Готовлю заполнитель и включаю режим заполнения, не забыв заменить карту на первоначальную:printf “BADSECTOR” > tmpfile
ddrescue –fill-mode=- tmpfile bad mapbad
И получаю еще один образ правильного размера! Как он это сделал для меня осталось загадкой, ведь я несколько раз пересчитал сумму размеров + блоков из карты, и она не совпадала с размером готового файла. И вот на месте отдающего магнитную душу богу уже его здоровый собрат, а я выполняю команды:losetup /dev/loop1 bad_new mdadm –assemble -o /dev/md12 /dev/loop1 /dev/sdd1
Но результат, мягко говоря, не тот, что я ожидал после 24 часов надежды на успех:mdadm: no RAID superblock on /dev/loop1
mdadm: /dev/loop1 has no superblock – assembly aborted
Что делать, попробуем теперь пообщаться с гуглом и разделами:#mdadm –examine /dev/loop1
mdadm: No md superblock detected on /dev/loop1.
— То есть как это no md superblock detected? — А у этого, который пока здоров?#mdadm –examine /dev/sdd1
/dev/sdd1: Magic : a92b4efc Version : 0.90.00 UUID : 64d38efd:b8e92c8c:f5292846:21864477 Creation Time : Fri Oct 10 20:22:23 2008 Raid Level : raid0 Raid Devices : 2 Total Devices : 2
Preferred Minor : 2 Update Time : Fri Oct 10 20:22:23 2008 State : active Active Devices : 2
Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Checksum : 6f768a67 – correct Events : 1 Chunk Size : 4K
— Версия 0.90.00? А где должен быть суперблок у mdadm 0.90.00? — В конце раздела.
— А как его прочитать с помощью mdadm?
— Никак. — То есть как это никак? Ну ладно, так где там он поточнее? — Не дальше 128K но не ближе 64К от конца раздела, выровнен по границе 64К, размер 4К.
Н-да, беру dd и проверяю:
dd if=/dev/sdd1 of=last128 bs=1024 skip=732571873 count=128
dd if=last128 of=bad_new bs=1024 seek=732571873 count=128
Да, суперблок записался в конец раздела по правильному адресу, но собираться массив с двумя одинаковыми суперблоками все равно не хочет, значит надо дать ему именно тот суперблок, с помирающего. Снова замена диска, только бы прочитался:#dd if=/dev/sdd1 of=last128 bs=1024 skip=732571873 count=128
dd: reading `/dev/sdd1': Input/output error
0+0 records in
0+0 records out
«Да, такого удара Великий комбинатор не испытывал никогда», — почему-то в памяти всплыла именно эта бессмертная цитата. Ну ладно, так легко мы не сдаемся. А мы вот так:dd if=/dev/sdd1 of=last128 bs=1024 skip=732571873 count=128 conv=noerror
Эх, размер last128 >0 но
Источник: https://habr.com/post/277239/