Zabbix: настройка мониторинга – элементы данных (items), графики (graphs), шаблоны (teamplates)
В предыдущей статье CentOS: установка, настройка Zabbix-agent и добавление нового хоста в мониторинг мы добавили новый хост в систему мониторинга, которую установили по статье CentOS: установка сервера мониторинга Zabbix.
Теперь пора заняться настройкой того, что именно мы хотим мониторить.
В примерах используется Zabbix с английским интерфейсом, но названия элементов и деталей в описании есть и на русском, что бы избежать путаницы.
В статье будет показано как:
- создавать группы хостов;
- создавать шаблоны целей мониторинга;
- создавать элементы данных;
- создавать группы элементов данных;
- создавать графики.
Когда я первый раз столкнулся с Zabbix-ом – то первое время путался в определениях, принятых в этой системе. Поэтому – отдельно несколько слов о принятых в ней именах объектов.
(teamplate) – это объект, содержащий в себе несколько (items), каждый из которых включает в себя определённые ключи (keys), по которым выполняется проверка хоста.
Кроме того, в шаблон можно включить:
- (applications) – по сути – тот же шаблон, но хранящий в себе только элементы данных (items);
- (triggers) – объект, обрабатывающий полученную информацию от элементов данных и на основе этой информации оценивающий состояние элемента хоста (например – состояние виртуальной памяти, или нагрузку на процессор) и, в зависимости от настройки, определяющий “важность” события;
- (graphs) – визуализированное представление полученной от элементов данных информации;
- (screens) – несколько объектов, сгруппированных для отображения на одной странице – графики, карты сети, состояние триггеров, простая текстовая информация.
Это – основные объекты шаблона, с которыми мы и будем работать дальше. Хотя у Zabbix есть множество других полезных вещей – мы начнём настройку мониторинга хоста с этих объектов.
Приступим к созданию шаблона.
В первую очередь нам необходимо определить – что именно мы хотим мониторить? Для первоначальной настройки сервера Zabbix возьмём стандартные данные, которые будут интересны при мониторинге любого сервера:
CPU – общая нагрузка на сервер (load avarage); количество процессов;
Memory – доступная и занятая физическая/виртуальная память;
Filesystem – доступное и занятое место на жестком диске сервера, скорость чтения с/на диски;
Network – количество полученной/переданной информации в байтах, количество пакетов, количество ошибок, счётчики “сброшенных” пакетов.
Особенный интерес (для автора, по крайней мере) представляет мониторинг Java, но примеры его настройки будут позже и в другой статье.
Потом можно будет добавить отдельный шаблон, который будет включать в себя набор объектов мониторинга Java-приложений и этот шаблон подключить к наблюдаемому хосту.
Другой вариант – добавить отдельную группу элементов данных, которую можно будет включить в создаваемый сейчас шаблон.
Теперь создадим новую группу хостов, для которой мы будем применять наш шаблон.
Переходим в раздел Configuration > Host groups, справа вверху нажимаем кнопку Create host group:
Задаём имя новой группе и определяем какие сервера будут к ней относится (это можно сделать позже, оставив группу пустой):
После нажатия кнопки Save мы возвращаемся к списку имеющихся групп, и видим созданную нами:
В колонке Members указаны хосты, состоящие в этой группе. Но поле Teampletes содержит (0) подключенных к этой группе шаблонов. Перейдём к созданию шаблона – Configuration > Teamplates, справа вверху нажимаем Create teamplate:
Заполняем поля Name (Имя шаблона), Visible name (Отображаемое имя), какая группа хостов и сервера будут связаны с этим шаблонов:
Во вкладке Linked teamplates можно выбрать уже существующие шаблоны, которые будут связаны с этим, но мы этого делать не будем, а создадим полностью новый шаблон.
Нажимаем Save, и возвращаемся к списку шаблонов, в начале списка которых видим наш – пока полностью пустой, если не считать связанного с ним хоста:
Приступим к созданию своих групп элементов данных, которые будут относится к нашему шаблону:
Кликаем по Applications:
На следующей странице видим что No applications defined и нажимаем Create application:
Начнём с набора для мониторинга CPU. Так как уже существует стандартная группа CPU, во избежание путаницы зададим имя, связанное с именем шаблона:
Жмём Save, возвращаемся в окно со списком имеющихся групп элементов данных:
Таким же образом создадим группы Memory_LMS, Network_LMS, Filesystem_LMS:
Теперь время приступить к самой интересной части – созданию непосредственно самих элементов данных. Кликаем на Items:
В следующем окне видим, что список элементов пустой и нажимаем Create item:
Остановимcя подробнее на этом моменте.
Host – имя хоста, группы хостов, шаблона или группы шаблонов, к которым будет принадлежать этот элемент;
Name – собственно, имя элемента;
Type – тип элемента, к которому будет он будет принадлежать, в данном случае – Zabbix agent (именно он будет собирать необходимые данные для этого элемента);
Key – , по которому будет определяться получаемая элементом данных информация. Очень удобно использовать стандартные ключи, нажав кнопку Select;
Type of information – тип получаемых данных. Если сомневаетесь какой именно использовать – можно посмотреть на , или в уже имеющихся элементах – например в шаблоне Template OS Linux имеется элемент Processor load (1 min average per core). Кликнув на нём – получите исходные данные, такие как ключ и тип информации:
Так же очень полезная опция – импорт существующего элемента. Для этого – в списке элементов отметьте необходимый, и слева внизу выберите Copy selected to:
В следующем окне выбираем группу, в которую мы хотим копировать элемент:
Теперь, если вернутся к списку связанных с нашим шаблонов элементов, мы увидим новый:
Units – специальное значение для обработки полученных данных перед их отображением, подробнее ;
Applications – к какой группе элементов данных будет относиться новый элемент;
Description – опционально, просто описание элемента;
Status – статус элемента после добавления.
Заполняем необходимые данные для нашего элемента. К примеру – создадим элемент, отслеживающий общее количество процессов:
Теперь у нас есть два элемента данных. Попробуем их визуализировать, что бы посмотреть что происходит на сервере. Нажимаем Graphs, что бы перейти к созданию графиков и на следующей странице выбираем Create graph:
Заполняем Name и подключаем элементы данных, которые будут отображаться в этом графике:
Посмотрим, что у нас получилось. Переходим в Monitoring > Graphs, выбираем Group, Host и созданный нами график:
На скриншоте видно, что присутствует уже готовый триггер, который скопировался вместе с элементом данных Processor load.
Но настройка триггеров – тема для отдельной статьи.
Что бы продемонстрировать график лучше – установим утилиту cpuburn:
# yum -y install cpuburn
И запустим её что бы увеличить нагрузку:
# for i in {1..2}; do burnK7 & done
[3] 9501
[4] 9502
Ждём некоторое время и смотрим на график ещё раз:
Теперь картина видна лучше.
В целом, на этом создание шаблона, элементов данных и графиков для сервера Zabbix можно считать выполненными.
В следующий раз приступим к настройке JMX-мониторинга и созданию/редактированию триггеров.
Источник: https://rtfm.co.ua/zabbix-nastrojka-monitoringa-elementy-dannyx-items-grafiki-graphs-shablony-teamplates/
Мониторинг состояния диска SSD Intel DC S3500
После установки на сервер диска SSD Intel DC S3500 необходимо было подключить его к системе мониторинга.
Для этого необходимо было обновить базу smartctl разобраться с параметрами и выбрать те которые будем мониторить.
Чтобы разобраться с параметрами нужно взять спецификацию на диск. Она нашлась по адресу http://www.intel.com/content/dam/www/public/us/en/documents/product-specifications/ssd-dc-s3500-spec.pdf
Как видно из спецификации для параметров мониторинга подходит несколько атрибутов:
Для удобства ориентации в документации индекс атрибута можно вывести в шестнадцатиричном виде:
[root@v03-t smartctl]# smartctl -A /dev/sdc | awk '/^ *[0-9]/{printf(“0x%02X %s
“,$1,$0)}' 0x05 5 Reallocated_Sector_Ct 0x0032 100 100 000 Old_age Always – 0 0x09 9 Power_On_Hours 0x0032 100 100 000 Old_age Always – 3177 0x0C 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always – 3 0xAA 170 Available_Reservd_Space 0x0033 100 100 010 Pre-fail Always – 0 0xAB 171 Program_Fail_Count 0x0032 100 100 000 Old_age Always – 0 0xAC 172 Erase_Fail_Count 0x0032 100 100 000 Old_age Always – 0 0xAE 174 Unsafe_Shutdown_Count 0x0032 100 100 000 Old_age Always – 1 0xAF 175 Power_Loss_Cap_Test 0x0033 100 100 010 Pre-fail Always – 651 (19 9204) 0xB7 183 SATA_Downshift_Count 0x0032 100 100 000 Old_age Always – 0 0xB8 184 End-to-End_Error 0x0033 100 100 090 Pre-fail Always – 0 0xBB 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always – 0 0xBE 190 Temperature_Case 0x0022 081 072 000 Old_age Always – 19 (Min/Max 13/28) 0xC0 192 Unsafe_Shutdown_Count 0x0032 100 100 000 Old_age Always – 1 0xC2 194 Temperature_Internal 0x0022 100 100 000 Old_age Always – 26 0xC5 197 Current_Pending_Sector 0x0032 100 100 000 Old_age Always – 0 0xC7 199 CRC_Error_Count 0x003e 100 100 000 Old_age Always – 0 0xE1 225 Host_Writes_32MiB 0x0032 100 100 000 Old_age Always – 302918 0xE2 226 Workld_Media_Wear_Indic 0x0032 100 100 000 Old_age Always – 2252 0xE3 227 Workld_Host_Reads_Perc 0x0032 100 100 000 Old_age Always – 51 0xE4 228 Workload_Minutes 0x0032 100 100 000 Old_age Always – 190640 0xE8 232 Available_Reservd_Space 0x0033 100 100 010 Pre-fail Always – 0 0xE9 233 Media_Wearout_Indicator 0x0032 098 098 000 Old_age Always – 0 0xEA 234 Thermal_Throttle 0x0032 100 100 000 Old_age Always – 0/0 0xF1 241 Host_Writes_32MiB 0x0032 100 100 000 Old_age Always – 302918 0xF2 242 Host_Reads_32MiB 0x0032 100 100 000 Old_age Always – 320022
Вот на основании полученных данных скрипт который прочитает SMART регистры диска Intel серии DC S3500 напишет о общем состоянии диска. В строке параметров команды printf лишние пробелы добавлены для того чтобы не ошибиться с количеством и расположением параметров.
#!/bin/bash smartctl -A /dev/sdc | awk -v prev=0 '/^22[5-8]/{ if ($1==225) { value[1]=($10-prev)*65535*512/1000000000 } else if($1==226) { value[2]=$10/1024 } else if($1==227) { value[3]=$10 } else if($1==228) { value[4]=$10 value[5]=$10/60/24 } }END{ printf(“The workload took %s minutes (%s days) to complete with %s%% reads and %s%% writes. A total of %sGB of data was written to the device, which increased the media wear in the drive by %s%%. At this point in time, this workload is causing a wear rate of %s%% for every %s minutes, or %s%%/hour.
“, value[4], value[5], value[3], 100-value[3], value[1], value[2], value[2], value[4], value[2]/value[4]*60); }'
А вот результат его работы:
The workload took 190640 minutes (132.389 days) to complete with 51% reads and 49% writes. A total of 10164.1GB of data was written to the device, which increased the media wear in the drive by 2.19922%. At this point in time, this workload is causing a wear rate of 2.19922% for every 190640 minutes, or 0.000692159%/hour.
А такой скрипт можно использовать в zabbix
!/bin/bash if [[ -z “$1” ]] ; then echo -e “ZABBIX PARAM NEED [?]” exit fi if [[ ! “$1” =~ ^sd[a-z]+$ ]] ; then echo -e “INVALID ZABBIX PARAM[$1]” exit fi if [ ! -b “/dev/$1” ] ; then echo -e “No block device “/dev/$1″ found” exit fi RESULT=`/usr/sbin/smartctl -A “/dev/$1” | awk '/^ *226/{printf(“%d
“, $10/1024)}'` if [ -z “${RESULT}” ] ; then echo -e “SMART Error” fi if [ “${RESULT}” -le 20 ] ; then echo “OK ${RESULT}” else echo “Wearout ${RESULT}%” fi
При уровне износа SSD диска до 20% будет возвращён статус “OK”. После 20% статус будет содержать процент износа.
Источник: http://youngblog.hoster-ok.com/monitoring-sostoyaniya-diska-ssd-intel-dc-s3500/
Первичная настройка системы мониторинга Zabbix (часть 1)
Если вы поставили Zabbix и не знаете что делать дальше – эта статья для вас! Нужно определиться какое оборудование есть в нашей сети и каким образом мы будем его мониторить. Допустим в сети есть серверы Linux и Windows, роутеры/коммутаторы Cisco или других производителей.
На серверы необходимо установить клиентскую часть – zabbix agent, активное сетевое оборудование будем мониторить по snmp.
Все это можно объединять в группы, группам присваивать шаблоны настроек, в шаблоны настроек добавлять элементы данных, которые необходимо мониторить, а на элементы данных устанавливать тригеры исходя из настроек которых мы будем получать уведомления (event).
Вместе с сервером мы установили на zabbix agent, это значит что наш сервер – является первым узлом который уже добавлен в систему мониторинга, но еще не мониторится. Давайте включим его мониторинг: “Настройка” – “Узлы сети” – изменить состояние “не наблюдается” на “наблюдается” просто кликнув по слову.
Далее заходим в настройки первого хоста который у нас уже есть, кликнув по имени сервера. Тут можно переименовать хост, сменить шаблон или добавить дополнительный шаблон, добавить профиль хоста, отредактировать адрес и т.п. Шаблон – объединяет группу параметров, которые необходимо мониторить. Лично я удалю группу Zabbix Server, т.к. у меня будет только один сервер с zabbix и перемещу свой сервер в группу Linux servers.
Давайте сейчас посмотрим как выглядят предоставляемые нам данные. Переходим в “Мониторинг” – “Последние данные”, можно отфильтровать узлы по группам и выбрать конкретный узел в группе
В шаблоне, элементы данных так же делятся на группы, такие как Availability, CPU, Filesystem… Предустановленный шаблон несет в себе слишком много элементов,
наша задача удалить те параметры которые нам бесполезны. Переходим в Настройка – Узлы сети –
делаем фильтр по шаблонам – выбираем шаблон Template_Linux – элементы данных.
Например операционная система установлена на один логический диск – поэтому оставляем только
“Free disk space on /”, а проверку на свободное место для отдельных директорий “Free disk space on /usr”
(и других) удаляем. Аналогично поступаем с остальными элементами данных
Выделяем и удаляем все проверки которые нам не нужны.
Почему нужно удалять/отключать не используемые элементы – для того чтобы не нагружать систему
ненужными нам проверками. Быстродействие сервера отображается на дашборде
Думаю теперь необходимо установить zabbix-agent на другие Linux серверы, делается это просто
- sudo apt-get install zabbix-agent
Источник: http://anton-lebedev.blogspot.com/2011/03/zabbix-1.html
ZABBIX — Мониторинг Windows Filesystem через FSNAME и FSTYPE
Долгое время мы не публиковали статей по Zabbix-у и не делали ничего по мониторингу через FSNAME и FSTYPE. Связано это с тем, что у нас было много еще задумок, которые мы смогли реализовать. Но теперь у нас есть время, и мы готовы подарить вам целый гайд на тему — Как мониторить Windows FileSystem через FSNAME.
Как настроить мониторинг Windows FileSystem через FSNAME в ZABBIX?
Для начала небольшой обзор: этот тип мониторинга относится к низкоуровневому обнаружению. Оно позволяет автоматически создавать элементы данных, триггеры и графики для различных объектов. Например необходимо мониторить Windows FileSystem и свободное место на дисках. Чтобы использовать #FSNAME нам необходимо проделать ряд действий. Давайте начнем.
Переходим по следующему пути: Настройки -> Шаблоны -> и на строке нужного шаблона нажимаем кнопку Обнаружение
На данной странице нажимаем кнопку: Создать правило обнаружения
На появившейся странице заполняем поля по стандарту. Особое внимание необходимо уделить полю «Ключ». В него обязательно нужно вписать vfs.fs.discovery. Так мы указываем, что ключу необходимо опрашивать файловые системы узла сети.
Переходим на вкладку «Фильтры», и здесь уже находим то, что нам необходимо. Нам необходим макрос {#FSNAME}. В первую строчку пишем следующие значения(фигурные скобки тоже копируем, кому необходимо):
{#FSNAME} совпадает/matshec ^C|^D|^E
Данный способ позволяет нам мониторить диски C;D;E; и сразу же к ним обращаться, если точнее, то значения описанные в поле напротив макроса это регулярные выражения. Подробнее о них вы можете узнать из гугла.
Нажимаем кнопку Добавит. Далее нас переносит обратно на страницу настройки правил обнаружения. Как только правило будет создано, нам необходимо создать прототип элемента данных этого правила со следующими параметрами:
Далее необходимо нажать на кнопку добавить. Обратите внимание на то, как используется макрос {#FSNAME}, где требуется указать имя файловой системы.
Когда правило будет обрабатываться, этот макрос будет заменен обнаруженной файловой системой.
Теперь проверяем обнаружение файловых систем перейдя по пути Мониторинг -> Последние данные -> Выбрать узел сети к которому был применен шаблон с обнаружением.
В моем случае определились абсолютно все файловые системы, которые были найдены на сервере gsasql29v. Таким образом мы можем подключать автообнаружение файловых систем к большому количеству серверов, что сократит развертывание мониторинга.
https://www.youtube.com/watch?v=Y2GVqn0Pb60На этом все, спасибо за внимание, подписывайтесь на нас в соц. сетях и конечно на наш Youtube — канал, видео на нем будет немного позже!
Поделиться в соц. сетях:
Источник: http://pechenek.net/sysmonitor/zabbix-monitoring-windows-filesystem-cherez-fsname-i-fstype/
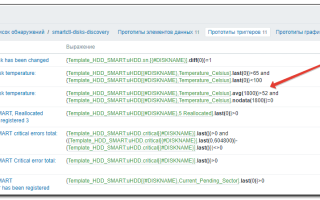
Мониторинг параметров S.M.A.R.T. в Zabbix | Записки системного администратора
1.Настройка скрипта на Zabbix-агенте
Создание папки для скриптов:
| # mkdir /etc/zabbix/scripts/ |
| # сhown root:zabbix -R /etc/zabbix/scripts/ |
| # chmod 750 /etc/zabbix/scripts/ |
Создание самого скрипта
| # nano /etc/zabbix/scripts/smart-stats.sh |
| 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647 | #!/bin/bashexport LC_ALL=””export LANG=”en_US.UTF-8″##### OPTIONS VERIFICATION #####if [[ -z “$1” || -z “$2” || -z “$3” ]]; then ##### DISCOVERY ##### DEVICES=`ls /dev | sed -e '/^([hs]d[a-z])$/!d'` if [[ -n $DEVICES ]]; then JSON=”{ “data”:[” SEP=”” for DEV in $DEVICES; do JSON=$JSON”$SEP{“{#HDNAME}”:”$DEV”}” SEP=”, ” done JSON=$JSON”]}” echo $JSON fi exit 0fi##### PARAMETERS #####RESERVED=”$1″DISK=”$2″METRIC=”$3″SMARTCTL=”sudo /usr/sbin/smartctl”CACHE_TTL=”55″CACHE_FILE=”/tmp/zabbix.smart.${DISK}.cache”EXEC_TIMEOUT=”1″NOW_TIME=`date '+%s'`##### RUN #####if [ -s “${CACHE_FILE}” ]; then CACHE_TIME=`stat -c”%Y” “${CACHE_FILE}”`else CACHE_TIME=0fiDELTA_TIME=$((${NOW_TIME} – ${CACHE_TIME}))#if [ ${DELTA_TIME} -lt ${EXEC_TIMEOUT} ]; then sleep $((${EXEC_TIMEOUT} – ${DELTA_TIME}))elif [ ${DELTA_TIME} -gt ${CACHE_TTL} ]; then echo “” >> “${CACHE_FILE}” # !!! DATACACHE=`${SMARTCTL} -A /dev/${DISK}` echo “${DATACACHE}” > “${CACHE_FILE}” # !!! chmod 640 “${CACHE_FILE}”fi#cat “${CACHE_FILE}” | grep -i “${METRIC}” | awk '{print $10}' | head -n1exit 0 |
Скрипт предусматривает кеш, что позволяет сократить количество реальных обращений к серверу.
Время действия кеша в секундах должно устанавливается чуть меньше чем период опроса элементов(по умолчанию в скрипте используется кеширование на 55 секунд, а интервал обновления элементов настроен на 60 секунд)
Установка прав
| # chown root:zabbix /etc/zabbix/scripts/smart-stats.sh |
| # chmod 550 /etc/zabbix/scripts/smart-stats.sh |
2.Настройка прав пользователю zabbix в sudo
| zabbix ALL=(ALL) NOPASSWD: /usr/sbin/smartctl |
Проверка локально с агента
| # sudo -u zabbix /etc/zabbix/scripts/smart-stats.sh none sda Temperature_Celsius |
3.Настройка Zabbix-агента
| # nano /etc/zabbix/zabbix_agentd.d/userparameter_smart.conf |
| ###SMART monitoringUserParameter=smart[*],/etc/zabbix/scripts/smart-stats.sh none “$1” “$2” |
| # service zabbix-agent restart |
Проверка с Zabbix-сервера
| # zabbix_get -s myservername -k 'smart[sda,Temperature_Celsius]' |
4.Настройка Zabbix-сервера
Для контролируемых данных в Zabbix нужно создать соответствующее элементы с типом «Zabbix агент» и ключом типа:
где dev — имя устройства, key — контролируемая метрика. Как альетрнатива:
Скачиваем, распаковываем и импортируем шаблон:
zabbix2_smart_template.zip Добавляем шаблон к хосту, на котором мониторим SMART-показатели. Проверяем,что через 1-2 минуты на хосте появились Item с именем S.M.A.R.T.
Monitoring->Latest Data->фильтруем по требуемому хосту в поле Hosts-> S.M.A.R.T.
Источник:
http://wiki.enchtex.info/howto/zabbix/zabbix_smart_monitoring
Источник: https://kamaok.org.ua/?p=1879
Zabbix: LLD-мониторинг железа под Windows на PowerShell
Пришло время и мне собрать свой велосипед для мониторинга физического состояния Windows-железок. Готового решения или хоть более или менее работающего найти не удавалось с момента моего знакомства с Zabbix, а это более 3 лет.
А тем более, чтобы оно было… элегантно что ли. Лично мне даже в таких вещах хочется видеть стройность и максимальную функциональность. Именно поэтому далее рассматривается только LLD и PowerShell. Ну и конечно же только бесплатное ПО.
Итак, мониторинг чего будет производиться:
- S.M.A.R.T. дисков (информация, общее состояние и отдельные показатели)
- Температуры, напряжение, обороты кулеров (на ваш выбор)
А выглядеть это все будет примерно так:
Суммарно понадобятся:
Шаблон
Под спойлером находится актуальный шаблон. Просто сохраните содержимое в формате xml и импортируйте в свой Zabbix.
Шаблон
3.2 2017-02-28T06:24:10Z Templates Hardware – Windows Hardware – Windows Необходимы компоненты: smartmontools (прописать Path), OHM (как сервис) Необходимые скрипты: windows.hard.ps1 -> C:SystemZabbixScripts UserParameter=ZScript[*],powershell C:SystemZabbixScriptswindows.$1.ps1 “$2” “$3” Templates Жесткие диски Оборудование Напряжение батареи BIOS 0 0 ZScript[hard,VBAT] 300 90 365 0 0 V 0 0 0 0 1 0 0 0 Оборудование Обнаружение кулеров 0 ZScript[hard,discovery,fan] 7200 0 0 0 0 0 0 3 Обороты кулера {#NAME} 0 0 ZScript[hard,{#ID},fan] 300 90 365 0 3 0 0 0 0 1 0 0 0 Оборудование {Hardware – Windows:ZScript[hard,{#ID},fan].last()}60 0 Высокая температура {#NAME} на {HOST.NAME}! 0 0 4 0 0 {Hardware – Windows:ZScript[hard,{#ID},temperature].last(#3)}>70 0 Слишком высокая температура {#NAME} на {HOST.NAME}! 0 0 5 0 0 Обнаружение датчиков напряжения 0 ZScript[hard,discovery,voltage] 7200 0 0 0 0 0 0 3 Напряжение {#NAME} 0 0 ZScript[hard,{#ID},voltage] 300 90 365 0 0 V 0 0 0 0 1 0 0 0 Оборудование Обнаружение дисков 0 ZScript[hdd,discovery] 7200 0 0 0 0 0 0 3 Диск {#DISKID} – SMART – Spin-Up Time [3] 0 0 ZScript[hdd,{#DISKID},3] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – Reallocated Sectors Count [5] 0 0 ZScript[hdd,{#DISKID},5] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – Seek Error Rate [7] 0 0 ZScript[hdd,{#DISKID},7] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – Power-on Time Count [9] (часов) 0 0 ZScript[hdd,{#DISKID},9] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – Spin-Up Retry Count [10] 0 0 ZScript[hdd,{#DISKID},10] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – G-sense error rate [191] 0 0 ZScript[hdd,{#DISKID},191] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – Температура [194] 0 0 ZScript[hdd,{#DISKID},194] 300 90 365 0 3 °C 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – Reallocation Event Count [196] 0 0 ZScript[hdd,{#DISKID},196] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – Current Pending Sector Count [197] 0 0 ZScript[hdd,{#DISKID},197] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – Uncorrectable Sector Count [198] 0 0 ZScript[hdd,{#DISKID},198] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – SMART – UltraDMA CRC Error Count [199] 0 0 ZScript[hdd,{#DISKID},199] 3600 90 365 0 3 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – Номинальная емкость 0 0 ZScript[hdd,{#DISKID},capacity] 3600 7 0 0 1 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – Семество 0 0 ZScript[hdd,{#DISKID},family] 3600 7 0 0 1 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – Версия FW 0 0 ZScript[hdd,{#DISKID},fw] 3600 7 0 0 1 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – Модель 0 0 ZScript[hdd,{#DISKID},model] 3600 7 0 0 1 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – Серийный номер 0 0 ZScript[hdd,{#DISKID},serial] 3600 7 0 0 1 0 0 0 0 1 0 0 0 Жесткие диски Диск {#DISKID} – Статус SMART 0 0 ZScript[hdd,{#DISKID},status] 300 7 0 0 1 0 0 0 0 1 0 0 0 Жесткие диски {Hardware – Windows:ZScript[hdd,{#DISKID},status].regexp(^PASSED$)}=0 0 SMART диска не пройден на {HOST.NAME} 0 0 4 0 0 {Hardware – Windows:ZScript[hdd,{#DISKID},194].last()}>55 0 Высокая температура диска на {HOST.NAME} 0 0 3 0 0 {Hardware – Windows:ZScript[hdd,{#DISKID},194].last()}>60 0 Опасная температура диска на {HOST.NAME} 0 0 4 0 0 {Hardware – Windows:ZScript[hard,VBAT].last(#3)} Для smartmontools# 2017/02/21 AcidVenom v2
# Скрипт для обнаружения дисков и получения их данных для Zabbix
param($1,$2) # Автообнарежение дисков
# Ключ: discovery
if ($1 -eq “discovery”) {
try {
$items = smartctl-nc –scan-open | where {$_ -match “/dev/sd”} write-host -NoNewline “{”
write-host -NoNewline “`”data`”:[” $n = 0
foreach ($obj in $items) { $n = $n + 1 if ((smartctl-nc -i $obj | ? {$_ -match “SMART support is: Enabled”}) -ne “”) { $line = “{`”{#DISKID}`”:`”” + ($obj.substring(5,3)) + “`”}” If ($n -lt $items.Count) { $line = “$line,”} write-host -NoNewline $line } }
write-host -NoNewline “]”
write-host -NoNewline “}” }
catch {exit}
} # Получение информации от дисков
# Ключи: else {
if ($2 -eq “status”) {
$obj = smartctl-nc -H /dev/$1 | where {$_ -match “result:”}
$obj = $obj.substring(50)
}
elseif ($2 -eq “model”) {
$obj = smartctl-nc -i /dev/$1 | where {$_ -match “Device Model:”}
$obj = $obj.substring(18)
}
elseif ($2 -eq “family”) {
$obj = smartctl-nc -i /dev/$1 | where {$_ -match “Model Family:”}
$obj = $obj.substring(18)
}
elseif ($2 -eq “fw”) {
$obj = smartctl-nc -i /dev/$1 | where {$_ -match “Firmware Version:”}
$obj = $obj.substring(18)
}
elseif ($2 -eq “serial”) {
$obj = smartctl-nc -i /dev/$1 | where {$_ -match “Serial Number:”}
$obj = $obj.substring(18)
}
elseif ($2 -eq “capacity”) {
$obj = smartctl-nc -i /dev/$1 | where {$_ -match “User Capacity:”} if ($obj -match “User Capacity:”) { $obj = $obj.Substring($obj.IndexOf(“[“)+1,$obj.IndexOf(“]”)-$obj.IndexOf(“[“)-1) } else { $obj = “N/A” }} # Получение показателей SMART
# Значения без скобок и их содержимого
else {
try {
$obj = smartctl-nc -A /dev/$1 | where {$_ -match “^ *$2”} try {$obj = $obj.Substring(87,$obj.IndexOf(“(“)-87)} catch {$obj = $obj.Substring(87)}
}
catch {$obj = “”}
}
Write-Output $obj
}
Обнаруживаются только диски с задействованным СМАРТом. Параметры запрашиваются из столбца «RAW_VALUE». Хотите мониторить другой параметр? Просто укажите его номер. По умолчанию скобки и их содержимое отбрасываются. Если нужный вам параметр диск не отдает, то возвращается пустое поле.
windows.hard.ps1 -> для OHM# 2017/02/13 AcidVenom v2
# Скрипт для обнаружения разных датчиков для Zabbix
param($1,$2) # Автообнарежение датчиков температуры, напряжения, оборотов кулеров
# Ключи: discovery temperature/voltage/fan
if ($1 -eq “discovery”) {
$items = Get-WmiObject -Namespace RootOpenHardwareMonitor -Class sensor | Where-Object {$_.SensorType -eq “$2” -and $_.Name -notmatch “#|VBAT” -and $_.Parent -notmatch “hdd”} write-host -NoNewline “{”
write-host -NoNewline “`”data`”:[” $n = 0
foreach ($obj in $items) { $n = $n + 1 $line = “{`”{#ID}`”:`”” + $obj.InstanceId + “`”, `”{#NAME}`”:`”” + $obj.Name + “`”}” If ($n -lt $items.Count) { $line = “$line,”} write-host -NoNewline $line
} write-host -NoNewline “]”
write-host -NoNewline “}” } # Зарезервированные переменные
# Ключи: VBAT
elseif ($1 -eq “VBAT”) { $obj = (Get-WmiObject -Namespace RootOpenHardwareMonitor -Class sensor | Where-Object {$_.Name -eq “$1”}).Value -replace(“,”,”.”) Write-Host -NoNewline $obj
} # Запрос значения по InstaceId от discovery
# else { if ((Get-WmiObject -Namespace RootOpenHardwareMonitor -Class sensor | Where-Object {$_.InstanceId -eq “$1”}).SensorType -eq “Voltage”) { $obj = (Get-WmiObject -Namespace RootOpenHardwareMonitor -Class sensor | Where-Object {$_.InstanceId -eq “$1”}).Value -replace(“,”,”.”)} else {$obj = (Get-WmiObject -Namespace RootOpenHardwareMonitor -Class sensor | Where-Object {$_.InstanceId -eq “$1”}).Value -replace(“,.*”,””)} Write-Host -NoNewline $obj
}
По умолчанию скрипт не обнаруживает названия датчиков, в которых есть #. Для чего это нужно, смотрите ниже.
Также зарезервировано одно имя датчика — Vbat. Это напряжение аккумулятора БИОС. Его значение вынесено в отдельный элемент для триггера (срабатывает если менее 2,9V).
Значения температур и оборотов кулеров на выходе целочисленные, значения напряжений передаются как есть.
Теоретически, можно обнаруживать и другие показатели (нагрузки, частоты,..). Используйте для этого соответствующий второй параметр в ключе. К примеру: ZScript[hard,discovery,load].
Подготовка Zabbix-агента
Для максимальной унификации я использую следующий и единственный параметр для своих скриптов:
UserParameter=ZScript[*],powershell C:SystemZabbixScriptswindows.$1.ps1 “$2” “$3”
Это дает максимальную гибкость и однообразность. Если нужно будет добавить еще параметров для каких-либо скриптов, можно просто добавить переменных в кавычках. На текущие работающие скрипты это никак не повлияет. Префикс windows я использую на всякий случай, мне так удобно хранить шаблоны для гарантированной идентификации.
smartmontools
Для мониторинга состояния дисков используется smartmontools (версия 6.5 на момент написания статьи). При установке ПО по умолчанию ставится утилита smartctl-nc — именно она используется в скрипте для облегчения жизни вашего сервера. Также потребуется прописать пусть к папке bin в переменных средах.
Путь просто добавляем в конец переменной Path через точку с запятой. По умолчанию — C:Program Filessmartmontoolsbin
OpenHardwareMonitor
Для датчиков же используется OHM. Софт бесплатный с открытым кодом. Установка тривиальна, но для полноценной работы необходимо запускать программу в качестве службы. Для подобных вещей есть NSSM, я бы все же советовал качать последнюю сборку.
А здесь можно посмотреть синтаксис.
Обещанный выбор датчиков обеспечивается за счет того, что названия датчиков можно изменять! Изменяете имена на удобочитаемые (они будут использованы в именах элементов), а ненужные датчики комментируете #.
Не забывайте перезапустить программу/службу для применения переименования.
Итого
В итоге получился неплохой инструмент для мониторинга. Желающие могут навесить свои триггеры на нужные прототипы элементов. Или же полностью переработать шаблон.
Источник: http://www.pvsm.ru/windows/246908
Как поставить на мониторинг температуру жесткого диска | Реальные заметки Ubuntu & Windows
В текущей заметке я разберу, как посредством системы мониторинга Zabbix мониторить как изменяется температура жесткого диска в текущей системе.
Большинство наработок я произвожу на своем домашнем ноутбуке HP dv6-3080er с системой Ubuntu 12.04.5 Desktop amd64 в роли графического окружения у меня выступает Gnome Classic.
Раз у меня включена для моего жесткого диска технология SMART, то посредством утилиты:
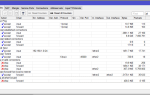
Приложения — Стандартные — Дисковая утилита получаю текущую информацию по моему жесткому диску. Ниже представлен скриншот информации.
Внимательно посмотрев на представленный скриншот вижу те данные которые мне нужно получить посредством вывода консольный утилит, а именно что текущая температура
жесткого диска — 45 градусов. (вроде нормально). Пробую поставить утилиту hddtemp в систему, чтобы с помощью нее извлечь данные по температуре, но применительно к моему диску — информация не извлекается.
keiz@dv6:~$ sudo apt-get install hddtemp -y
keiz@dv6:~$ sudo hddtemp /dev/sda
ВНИМАНИЕ: Диск /dev/sda не дает показания температурного датчика.
ВНИМАНИЕ: Это еще не значит, что у него его нет.
ВНИМАНИЕ: Если вы точно знаете, что датчик есть, напишите hddtemp@guzu.net
ВНИМАНИЕ: (см. опции —help, —debug и —drivebase).
/dev/sda: TOSHIBA MK5056GSY: нет датчика
А посредством другой утилиты из набора SMART:
keiz@dv6:~$ sudo smartctl -a /dev/sda | grep 190
190 Airflow_Temperature_Cel 0x0022 056 041 045 Old_age Always In_the_past 44 (Min/Max 26/45)
Т.е. Текущая температура моего ноутбучного жесткого диска 45 градусов цельсия. Но так ли это на самом деле, почему-то другие источники консольного типа мне вообще ничего не выводят. А потому нужно поискать еще какие нибудь консольные утилиты чтобы это подтвердить.
Проанализировав еще много разных утилит остановился на этой: — HDSentinel
Расшифровывается аббревиатура hdsentinel, как Hard Disk Sentinel Linux Edition (FREE). Возможности данной утилиты состоят в следующем, с ее помощью можно извлекаеть температуру и жизненную информацию со следующих типов:
IDE, S-ATA (SATA II also), SCSI and USB жестких дисков подключенных как к материнской плате так и внешним контроллерам.
В стандартных репозитариях данной утитилы к сожалению нет, поэтому выкачиваем ее с официального сайта:
keiz@dv6:~/test$ wget http://www.hdsentinel.com/hdslin/hdsentinel.gz
keiz@dv6:~/test$ gzip -d hdsentinel.gz
keiz@dv6:~/test$ chmod +x hdsentinel
keiz@dv6:~$ file test/hdsentinel
test/hdsentinel: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), stripped
Для удобства перенесу данную утилиту в каталог /bin:
keiz@dv6:~/test$ sudo mv hdsentinel /bin
Теперь с ее помощью выведу информацию по своему жесткому диску:
keiz@dv6:~$ sudo hdsentinel
Hard Disk Sentinel for LINUX console 0.03 (c) 2008-2009 info@hdsentinel.com
Start with -r [reportfile] to save data to report, -h for help
Examining hard disk configuration …
HDD Device 0: /dev/sda
HDD Model ID : TOSHIBA MK5056GSY
HDD Serial No: 40L8FBOTS
HDD Revision : LH003C
HDD Size : 476940 MB
Interface : S-ATA II
Temperature : 43 °C
Health : 100 %
Performance : 100 %
Power on time: 69 days, 4 hours
Est. lifetime: more than 1000 days
Вот теперь уже лучше и можно посредством некоторых утилит форматирования получить температуру жесткого диск в виде конечного числа:
keiz@dv6:~$ sudo hdsentinel -solid | awk '{print $2, $1, $5}' | grep -v “^?” | sort -nr
43 /dev/sda TOSHIBA_MK5056GSY
keiz@dv6:~$ sudo hdsentinel -solid | awk '{print $2}' | grep -v “^?” | sort -nr
43
Теперь перехожу к подготовке элемента данных для текущего хоста на предмет слежения за температурой моего жесткого диска: (тут все просто ниже пошаговая инструкция как это сделать)
http://IP&DNS/zabbix — Configuration — Hosts — выбираю свой хост: Zabbix server — потом перехожу на Items (элемент данных) — Create Item (создаю новый)
- Name: HDD /dev/sda
- Type: Zabbix agentd.conf
- Key: hdd
- Host interface: 127.0.0.1:10050
- Type of information: Numeric (unsigned)
- Data type: Decimal
- Applications: Monitoring (это я ранее предварительно создал группу)
- Enabled: отмечаем галочкой
А после как основные параметры определены для текущего элемента данных нажимаю Save для сохранения внесенных изменений.
Ниже подготавливаю конфигурационный файл для осуществления взаимодействия скриптовой части по извлечению числового выражения температуру жесткого диска которое будет передаваться на Zabbix и уже визуализироваться посредством наглядного графика.
keiz@dv6:~$ sudo nano /usr/lib/zabbix/externalscripts/hdd
#!/bin/bash
sudo hdsentinel -solid | awk '{print $2}' | grep -v “^?” | sort -nr
exit
keiz@dv6:~$ sudo chmod +x /usr/lib/zabbix/externalscripts/hdd
keiz@dv6:~$ sudo nano /etc/zabbix/zabbix_agentd.conf
UserParameter=hdd[*],/usr/lib/zabbix/externalscripts/hdd
keiz@dv6:~$ sudo service zabbix-server restart
keiz@dv6:~$ sudo service zabbix-agent restart
Проверяю, что созданный скрипт отрабатывает на основе внесенных дополнений в конфигурационный файл Zabbix агента:
keiz@dv6:~$ sudo zabbix_agentd -c /etc/zabbix/zabbix_agentd.conf -t hdd
hdd [t|43]
Отлично Zabbix понимает подготовленный для него скрипт на предмет мониторинга температуры жесткого диска.
Проверю, что созданный элемент данных активировался:
http://IP&DNS/zabbix — Configuration — Hosts — Zabbix server — Items и находим только что созданный:
но как видно, он еще не завелся, в большинстве случаем с которыми мне приходилось сталкиваться когда я настраивал новые элементы данных помогала повторная перезагрузка сервисов (иногда но не всегда, может у Вас все быть настроено корректно и верно, а система Web-интерфейс Zabbix показывает что все не так, идет ошибка — просто перезагрузите систему):
keiz@dv6:~$ sudo service zabbix-server restart
keiz@dv6:~$ sudo service zabbix-agent restart
keiz@dv6:~$ sudo zabbix_agentd -c /etc/zabbix/zabbix_agentd.conf -t hdd
hdd [t|43]
хм странно информация через консоль воспринимается, а в Web-интерфейсе почему-то нет. Если что то не заработало, как надо сразу на помощь приходят логи. Анализирую логи агента и обнаруживаю что нет возможность выполнить, как я правильно понимаю из скрипта hdd команду hdsentinel с первым ключом это повышения прав через sudo.
keiz@dv6:~$ sudo tail -f /var/log/zabbix/zabbix_agentd.log
sudo: нет tty и не указана программа askpass
sudo: нет tty и не указана программа askpass
The more you drive — the dumber you get.
На заметку: по умолчанию пользователь Zabbix не имеет прав перезапускать системные сервисы
Также надо включить удаленное выполнение команд Zabbix’ом, для этого в конфигурационном файле Zabbix агента следует активировать параметр: EnableRemoteCommands
keiz@dv6:~$ sudo nano /etc/zabbix/zabbix_agentd.conf
EnableRemoteCommands=1
после перезапустить демон агента:
keiz@dv6:~$ sudo service zabbix-agent restart
Для исправления данной ситуации нужно учетной записи zabbix разрешить запуск утилиты hdsentinel с использованием повышения прав:
keiz@dv6:~$ sudo nano /etc/sudoers
Defaults:zabix !requiretty
zabbix ALL=(ALL) NOPASSWD: /bin/hdsentinel
Теперь снова перезапускаю сервисы Zabbix для перечивания внесенных изменений:
keiz@dv6:~$ sudo service zabbix-server restart
keiz@dv6:~$ sudo service zabbix-agent restart
Теперь по прошествии некоторого количества времени или форсированной нагрузки на подсистему работу жесткого диска снова переключаемся на Zabbix интерфейс для отображения визуализации снимаемых данных о температуре:
http://IP&DNS/zabbix — Monitoring — Latest data
Group: Zabbix servers
Host: Zabbix server
Разворачиваю категорию Monitoring — нахожу элемент данных HDD /dev/sda и нажимаю Graph и то что мне нужно было — график изменения температуры жесткого диск с учетом изменяемого настоящего времени.
Работает. Цель заметки достигнута. Теперь я могу для себя знать как меняется температура моего жесткого диска на ноутбуке в зависимости от выполняемых задач, если греется он очень уж сильно то возможно стоит убрать его с колен или с дивана, т. к.
оттот горячего воздуха не производится должным образом. Да и плюс в этой заметке, что на основе этой смогу сделать еще что-нибудь более интересное и значимое, это так называемый задел на будующее. А мой блог — как раз и есть отражение этого.
Не буду Вас задерживать и до встречи, с уважением, автор блога — ekzorchik.
Источник: http://www.ekzorchik.ru/2015/04/how-to-put-on-the-hard-drive-temperature-monitoring/