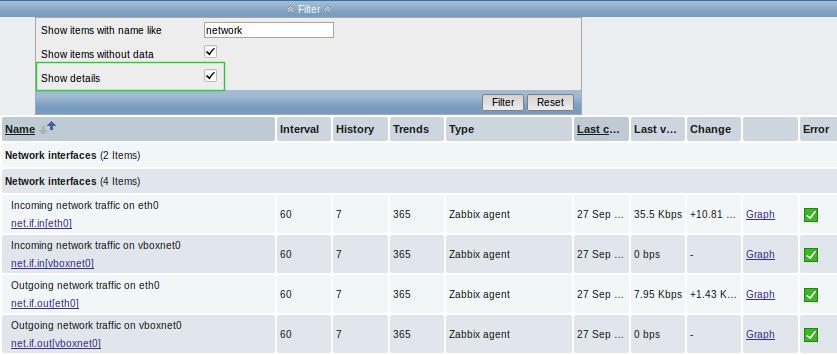
11 Оптимизация производительности [Zabbix Documentation 2.2]
ru:manual:appendix:performance_tuning
Данный раздел в разработке.
Очень важно, чтобы система Zabbix была оптимизирована для получения максимальной производительности.
Типовые советы по выбору аппаратной конфигурации:
- Используйте самый быстрый процессор из доступных
- SCSI или SAS лучше чем IDE (производительность IDE дисков может быть значительно улучшена с помощью утилиты hdparm) и SATA
- 15К RPM лучше чем 10К, которые в свою очередь лучше чем 7200 RPM
- используйте быстрое RAID хранилище
- используйте быстрый Ethernet адаптер
- большее количество ОЗУ всегда лучше
- Используйте последнюю (стабильную!) версию ОС
- Отключите ненужный функционал в ядре
- Оптимизируйте настройки ядра
Можно оптимизировать многие параметры для получения оптимальной производительности.
StartPollers
Основное правило – использовать как можно меньшее значение. Каждый лишний процесс zabbix добавляет определенную нагрузку, В то же время, распараллеливание увеличивается.
Оптимальное количество процессов достигается, когда очередь, в среднем, содержит минимальное количество параметров (идеально, 0 в любой момент времени).
За этим значением можно следить, используя внутренний элемент данных zabbix[queue].
Смотрите раздел “смотрите также” внизу этой страницы, чтобы понять как настроить оптимальное количество zabbix процессов.
DebugLevel (Уровень журналирования)
Оптимальное значение 3.
DBSocket (Сокет базы данных)
Только для MySQL. Для соединения с базой данных рекомендуется использовать DBSocket. Это более быстрый и более защищенный путь.
Это возможно наиболее важная часть оптимизации Zabbix. Zabbix сильно зависит от доступности и производительности базы данных.
- используйте наиболее быстрый движок, т.е. MySQL или PostgreSQL
- используйте стабильный выпуск базы данных
- скомпилируйте MySQL или PostgreSQL из исходных кодов для получения максимальной производительности
- следуйте рекомендациям инструкций по оптимизации настроек из документации MySQL или PostgreSQL
- для MySQL, используйте InnoDB структуру таблиц
- Zabbix работает как минимум в 1,5 раза быстрее (по сравнению с MyISAM), если используется InnoDB. Такое поведение достигается из-за увеличенного распараллеливания запросов. Тем не менее, InnoDB требует большую производительность процессора.
- настоятельно рекомендуется оптимизировать настройки сервера базы данных для получения лучшей производительности.
- держите таблицы базы данных на разных жестких дисках.
- наиболее тяжелыми таблицами являются 'history', 'history_str, 'items' 'functions', triggers', и 'trends'
- для больших инсталляций хранение временных файлов MySQL в tmpfs:
- MySQL >= 5.5: не рекомендуется (MySQL bug #58421 [en])
- MySQL < 5.5: рекомендуется
Проблемы связанные с производительностью веб-интерфейса можно диагностировать при помощи режима отладки веб-интерфейса.
- наблюдайте только необходимые параметры
- оптимизируйте “Интервал обновления” по всем элементам данных. Использование небольшого интервала обновления может быть удобно для приятных графиков, но небольшой интервал обновления может перегрузить Zabbix
- оптимизируйте параметры стандартных шаблонов
- оптимизируйте параметры очистки истории
- не наблюдайте параметры возвращающие одни и те же значения
- избегайте использования триггеров с большими периодами в функциях. Например, max(3600) будет вычисляться намного медленнее, чем max(60).
Zabbix 2.2 внёс новую функцию – процессы отображают в командной строке текущую активность и значимую статистику, примерно так:
UID PID PPID C STIME TTY TIME CMD
zabbix22 4584 1 0 14:55 ? 00:00:00 zabbix_server -c /home/zabbix22/zabbix_server.conf
zabbix22 4587 4584 0 14:55 ? 00:00:00 zabbix_server: configuration syncer [synced configuration in 0.041169 sec, idle 60 sec]
zabbix22 4588 4584 0 14:55 ? 00:00:00 zabbix_server: db watchdog [synced alerts config in 0.018748 sec, idle 60 sec]
zabbix22 4608 4584 0 14:55 ? 00:00:00 zabbix_server: timer #1 [processed 3 triggers, 0 events in 0.007867 sec, 0 maint.periods in 0.005677 sec, idle 30 sec]
zabbix22 4609 4584 0 14:55 ? 00:00:00 zabbix_server: timer #2 [processed 2 triggers, 0 events in 0.004209 sec, idle 30 sec]
zabbix22 4637 4584 0 14:55 ? 00:00:01 zabbix_server: history syncer #4 [synced 35 items in 0.166198 sec, idle 5 sec]
zabbix22 4657 4584 0 14:55 ? 00:00:00 zabbix_server: vmware collector #1 [updated 0, removed 0 VMware services in 0.000004 sec, idle 5 sec]
zabbix22 4670 1 0 14:55 ? 00:00:00 zabbix_proxy -c /home/zabbix22/zabbix_proxy.conf
zabbix22 4673 4670 0 14:55 ? 00:00:00 zabbix_proxy: configuration syncer [synced config 15251 bytes in 0.111861 sec, idle 60 sec]
zabbix22 4674 4670 0 14:55 ? 00:00:00 zabbix_proxy: heartbeat sender [sending heartbeat message success in 0.013643 sec, idle 30 sec]
zabbix22 4688 4670 0 14:55 ? 00:00:00 zabbix_proxy: icmp pinger #1 [got 1 values in 1.811128 sec, idle 5 sec]
zabbix22 4690 4670 0 14:55 ? 00:00:00 zabbix_proxy: housekeeper [deleted 9870 records in 0.233491 sec, idle 3599 sec]
zabbix22 4701 4670 0 14:55 ? 00:00:08 zabbix_proxy: http poller #2 [got 1 values in 0.024105 sec, idle 1 sec]
zabbix22 4707 4670 0 14:55 ? 00:00:00 zabbix_proxy: history syncer #4 [synced 22 items in 0.008565 sec, idle 5 sec]
zabbix22 4738 1 0 14:55 ? 00:00:00 zabbix_agentd -c /home/zabbix22/zabbix_agentd.conf
zabbix22 4739 4738 0 14:55 ? 00:00:00 zabbix_agentd: collector [idle 1 sec]
zabbix22 4740 4738 0 14:55 ? 00:00:00 zabbix_agentd: listener #1 [waiting for connection]
zabbix22 4741 4738 0 14:55 ? 00:00:00 zabbix_agentd: listener #2 [processing request]
Основной процесс является исключением. Вместо текущей активности отображается изначальная командная строка. Такое поведение помогает разделять в системе процессы с несколькими экземплярами Zabbix.
Такая возможность не реализована на платформах Microsoft Windows.
Если уровень журналирования указан равным DebugLevel=4, подобные сообщения о активности и статистике также записываются в файл журнала.
В системах Linux команда ps может использоваться с командой watch для наблюдения, что делает Zabbix. Например, запуска команды ps 5 раз в секунду для наблюдения за активностью процессов:
watch -n 0.2 ps -fu zabbix
Наблюдение только за процессами Zabbix прокси и агента:
watch -tn 0.2 'ps -f -C zabbix_proxy -C zabbix_agentd'
Наблюдение только за процессами history syncer:
watch -tn 0.2 'ps -fC zabbix_server | grep history'
Команда ps предоставляет широкий вывод (примерно 190 символов), который требуется для некоторых сообщений активности. Если ваш терминал имеет менее чем 190 символов для текста, вы можете попробовать следующий способ:
watch -tn 0.2 'ps -o cmd -C zabbix_server -C zabbix_proxy -C zabbix_agentd'
для отображения только полезной информации без UID, PID, времени старта и прочего.
Можно также использовать команду top для наблюдения за производительностью Zabbix. Нажатие клавиши 'c' в команде top отобразит процессы с их командами строками. В наших тестах в Linux top и atop отображают корректно изменения активности процессов Zabbix, но в htop смена активности не отображалась.
Если команда watch не установлена, подобный вывод можно получить следующим способом:
while [ 1 ]; do ps x; sleep 0.2; clear; done
Если команда watch не доступна, можно использовать следующий метод:
while [ 1 ]; do ps -fu zabbix; sleep 1; clear; done
По умолчанию команда ps не отображает изменения активности. Вместо этой команды можно использовать /usr/ucb/ps. Если команда watch не установлена, периодическое обновление списка процессов может выполнить следующим сособом:
while [ 1 ]; do /usr/ucb/ps gxww; sleep 1; clear; done
В Solaris 11:
- /usr/ucb/ps по умолчанию не установлен. Вам возможно потребуется установить ucb пакет, т.е. pkg install compatibility/ucb,
- если демон Zabbix запускается от привилегированного пользователя, его активность не отображается непривилегированному пользователю.
- команда sleep принимает не только секунды, но также и дроби секунд (т.е. sleep 0.2).
- Как настроить оптимальное количество zabbix процессов
Источник: https://www.zabbix.com/documentation/2.2/ru/manual/appendix/performance_tuning
Настройка производительности больших баз данных mysql для zabbix
“running 16k values per second” – Вы имеете в виду «строки, вставленные в секунду»? SELECTs в секунду? Что-то другое?
Наиболее важным параметром для MySQL является innodb_buffer_pool_size, что, вероятно, должно быть 300G для вашей установки. innodb_buffer_pool_instances=16.
innodb_flush_log_at_trx_commit по умолчанию. 1 безопаснее; 2 приводит к меньшему количеству ввода-вывода.
Если вы делаете 16K INSERTs в секунду, существует несколько способов уменьшения ввода-вывода (что вы подразумеваете «слишком высоко»). Группировка (выполняется несколько строк в одном INSERT), помещая их в одну транзакцию, используя LOAD DATA или «этап». Пожалуйста, опишите больше.
ПЕРЕМЕННЫЕ/Анализ состояния
Были некоторые интересные вещи. Вот основные моменты:
(innodb_max_dirty_pages_pct) = 30 – Когда buffer_pool начинает промываться на диск – Почему так низко? (Вероятно, не имеет значения)
((Innodb_buffer_pool_reads + Innodb_buffer_pool_pages_flushed)) = ((23406029 + 990332255))/769924 = 1316 /sec – InnoDB I/O – Увеличить innodb_buffer_pool_size? Увеличить innodb_max_dirty_pages_pct?
(Created_tmp_tables) = 300,386,596/769924 = 390 /sec – Частота создания таблиц «темп» как часть сложных SELECT.
(Created_tmp_disk_tables) = 16,281,268/769924 = 21 /sec – Частота создания диска «временные» таблицы в составе сложных – SELECT, увеличение tmp_table_size и max_heap_table_size.
Проверьте правила для временных таблиц, когда MEMORY используется вместо MyISAM. Возможно, незначительные изменения схемы или запроса могут избежать MyISAM.
Более эффективные индексы и переформулировка запросов, скорее всего, помогут.
(Select_scan) = 22,715,682/769924 = 30 /sec – полное сканирование таблицы – Добавить индексы/оптимизацию запросов (если они не являются крошечными столами)
(Sort_merge_passes) = 412,662/769924 = 0.54 /sec – Heafty видов – Увеличение sort_buffer_size и/или оптимизации сложных запросов.
(long_query_time) = 10.000000 = 10 – Cutoff (Seconds) для определения «медленного» запроса. – Предложите 1 (и включите slowlog) – помогли бы найти непослушные запросы.
Threads_running = 45 – вероятно, чтобы указать, что запросы спотыкаясь друг с другом
Innodb_buffer_pool_pages_flushed/Questions = 0.49 – Может быть, указывает buffer_pool не является эффективным кэш.
Select_range/Com_select = 22% – Высокий, но не обязательно плохой. (Select_range = 360/sec)
Opened_files = 86/sec. Меня беспокоит table_open_cache, но нет указателей, чтобы указать, достаточно ли он «достаточно большой».
Можете ли вы группировать записи в более крупные транзакции? Существует много операций ввода-вывода; это уменьшит его. Com_begin и Com_commit в настоящее время 257/сек.
Многие из них являются UPDATEs. Пожалуйста, уточните, что они делают. Если они увеличивают счетчики, возможно, стоит их каким-то образом собрать.
innodb_io_capacity = 6000 – Я не знаю, оптимально ли это для вашей системы.
Innodb_x_lock_spin_waits = 5500/sec – Огромное количество, но у меня нет хорошей ручки, что с этим делать.
large_page_size – Я не испытал этого; как это будет для вас?
slave_skip_errors = 1062 – Возможно, вам нужно использовать INSERT IGNORE или INSERT .. ON DUPLICATE KEY UPDATE..?
Slow журнал
Многие из этих запросов имеют
from items t,hosts r where t.hostid=r.hostid and r.proxy_hostid=13242 and r.status in (0,1) and t.type in (0,7,1,4,6,12,2,3,9,10,11,13,14,16,17,5) order by t.itemid
который нуждается в этих составных индексов:
items: INDEX(hostid, type) — in this order hosts: INDEX(proxy_host_id, status, hostid) — this order; helps WHERE; 'covering'
Мои и подбрасывать KEY hosts_3, так как это будет излишним.
Я вижу случаи избыточных индексов, таких как
KEY 'c_items_4' ('interfaceid'), KEY 'items_6' ('interfaceid'),
Рекомендуют DROPping один из них.
Есть проблемы со многими другими таблицами, но я не буду вдаваться в них; Zabbix должен их исправить.более
UPDATE item_discovery … WHERE itemid BETWEEN … AND … OR itemId IN (…);
Это, вероятно, очень неэффективно из-за OR. Лучшее решение (для MySQL, не знаю, о Zabbix), чтобы разбить его на два UPDATEs:
UPDATE item_discovery … WHERE itemid BETWEEN … AND …; UPDATE item_discovery … WHERE itemId IN (…);
более 2
Это не должно занять 6-10 секунд, чтобы вставить 1000 (?) строк в один раздел таблицы. Это может помочь, если вы ограничили эти вставки до 100 строк за раз.
более 3
Форсирование запросы, как указано выше, поможет в любом случае. Но теперь у меня другая проблема.
Этот медленный фрагмент от одного 30-минутного периода? И это был какой-то шип, который обычно не случается? Что это, когда вы достигли Max_used_connections = 523? Что происходит в таком случае: 523 потока, все получающие небольшую долю 32 ядер и т. Д., Спотыкаются друг над другом. Я вижу несколько запросов, занимающих более 3 секунд, но они не должны принимать более 3 миллисекунд.
В таких ситуациях я рекомендую выяснить, как ограничить количество подключений upstream, то есть в клиенте Zabbix. Между тем, вы можете уменьшить max_connections, скажем, 200. Это, скорее всего, вызовет клиента; но это может быть лучше, чем длительный период, когда ничего не происходит.
Кроме того, 5.5 становится довольно старым; начать планировать модернизацию.
Настя УДАЛИТЬ
@ 12: 37 (и, возможно, каждый хх: 37) существует 123-вторая отделка запроса:
DELETE FROM events WHERE source = 0 AND object = 0 AND clock < ...;
Несмотря на то, что это оптимальный показатель для такого
KEY 'events_2' ('source','object','clock')
Это, очевидно, недостаточно. 123 секунды диск-интенсивных удалений, включая материал отката здания, могут замедлить другие вещи, что, я думаю, и произошло.
Лечит?
План A: вместо того, чтобы делать DELETE почасово, делайте это каждые, скажем, 5 минут (с разным clock обрезанием каждый раз). Это должно ускорить его до 10 секунд вместо 123, возможно, быстрее.
План B: Сделать это PARTITIONed столом и использовать DROP PARTITION, что намного менее интенсивно работает в системе. (Но это добавляет много сложности, и Zabbix, вероятно, будет мешать.)
План C: «Постоянно» удалять материал, используя другой процесс.Возможно
Loop: DELETE FROM events WHERE source = 0 AND object = 0 AND clock < ... -- update this cutoff as needed LIMIT 1000; sleep 1 second repeat
План D: Смотрите мой Big Delete блог для других методов (и некоторые подробности о планах A, B, C)
продолжать преследовать другие предложения; вы, вероятно, близки к точке разрыва. То есть, если набор данных удваивается по размеру, ничто не вернет систему к жизни. Мои различные предложения будут задержка, но не устранить the doomsday.
Источник: https://dba.stackovernet.com/ru/q/43370
Zabbix – Zabbix + Housekeeper + PostgreSQL + Vacuum
 7 января 2012 (обновлено 2 ноября 2014)OS: Linux Debian Lenny/Squeeze.Application: Zabbix Server 1.8/2.0.Задача: явно настроить контроль за объёмом используемого Zabbix-сервером и СУБД PostgreSQL дискового пространства при обеспечении работы сервиса мониторинга.
7 января 2012 (обновлено 2 ноября 2014)OS: Linux Debian Lenny/Squeeze.Application: Zabbix Server 1.8/2.0.Задача: явно настроить контроль за объёмом используемого Zabbix-сервером и СУБД PostgreSQL дискового пространства при обеспечении работы сервиса мониторинга.
По умолчанию, “действия” и “события” системы мониторинга Zabbix не хранятся более 365 дней.
Этот параметр можно произвольно изменять в процессе конфигурирования каждого элемента мониторинга индивидуально или задавать обобщение с помощью шаблона; ничто не мешает нам задать для какого-нибудь параметра срок хранения данный в течении одного дня, например.
Для удаления данных с истёкшим сроком хранения в Zabbix-сервере есть специальная подсистема, называемая “Housekeeper”. Регулярно, в соответствии с заданными параметрами, подсистема отрабатывает удаление старых данных. Всё просто, настраиваемо в общем конфигурационном файле Zabbix:
# cat /etc/zabbix/zabbix_server.conf
….# Зададим периодичность запуска процедуры очистки базы Zabbix от устаревшей информации (в часах). Учитывая то, что мы используем в качестве СУБД PostgreSQL, период задаём побольше, чтобы дать время утилите “vacuum”, которая должна оптимизировать таблицы базы после удаления части содержимого, отработать в полном объёме#HousekeepingFrequency=24# Зададим ограничение на количество удаляемых за один проход записей. Полагаю, что это значение нужно подбирать исходя их общего количества отрабатываемых узлов и производительности дисковой подсистемы. По умолчанию значение равно 500 (пятистам), что мне представляется слишком малым#MaxHousekeeperDelete=2500 # Отключаем отключение процедуры очистки (такой вот забавный подход, значение “true”, она же “1” – отключает подсистему)#DisableHousekeeping=0
….
Ничто не совершенно; это касается и способа запуска утилиты очистки баз Zabbix от устаревшей информации. К сожалению, нельзя явно задать время старта “Housekeeper”; можно лишь задавать время относительно предыдущего запуска. А как было бы хорошо задать старт очистки в середине ночи, чтобы к утру уже завершилась как очистка, так и последующая оптимизация с помощью “vacuum”.
После удаления части данных таблицы “фрагментируются”. Не будем здесь говорить о том, как это сказывается на характеристиках скорости доступа к таблице, заметка больше о проблеме разрастания таблиц баз в размере. PostgreSQL последних версий, с интегрированным и настроенным “autovacuum” (что уже сделано по умолчанию, в Debian Lenny для PostgreSQL 8.3/8.
4, например), самостоятельно пытается оптимизировать таблицы, перераспределяя данные и размечая как доступное высвобожденное пространство, занятое ранее удалёнными данными, отслеживая изменения на уровне таблиц.
Оно вроде-бы и хорошо, в принципе, но на деле настройки по умолчанию побуждают запускаться “vacuum” каждую минуту, дёргая базу ради обработки двадцати-тридцати строк, больше тормозя систему целом, нежели давая какой-то выигрыш в производительности.
Понятно, что в большом, сложном “enterprise” проекте, со множеством сервисов, изменяющемся функционале, часто подвергающемся масштабированию, стоит настроить “autovacuum”, отвечающий общим потребностям и целям; проще потерять чуть-чуть на автоматизации, чем вручную выискивать слабые места – но не в нашем случае, со “standalone” сервером мониторинга.
Не уверен, но не думаю, чтобы кто-то эксплуатировал нагруженный Zabbix-сервер, разделяя ресурсы СУБД PostreSQL с другими сервисами. По сути, “база данных” – самое узкое место в разветвлённой системе мониторинга, от неё добиваются максимальной производительности при том, что задачи СУБД ограничены и ручная настройка ряда параметров вполне приемлема.
В общем, я предлагаю отключать “autovacuum” в PostgreSQL, в том случае, если кроме Zabbix её более никто не использует, планируя процедуру оптимизации на то время, когда система мониторинга предположительно наименее загружена обработкой поступающих и запрашиваемых данных.Оптимизируем параметры запуска PostgreSQL, позволяющие более эффективно отрабатывать утилите “vacuum” и отключаем функционал “autovacuum”:
# cat /etc/postgresql/8.4/main/postgresql.conf
….# Задаём размер области памяти, выделяемой для операций VACUUM, CREATE INDEX, ALTER TABLE и FOREGIN KEY (при общем объёме ОЗУ в 4Gb рекомендуется выделить около 512MB)#maintenance_work_mem = 512MB….# Выключаем “autovacuum”#autovacuum = off
….
Останавливаем Zabbix-сервер, перезапускаем PostgreSQL и снова запускаем Zabbix-сервер:# /etc/init.d/zabbix-server stop# /etc/init.d/postgresql restart
# /etc/init.d/zabbix-server start
Теперь, когда PostgreSQL не осуществляет более автоматическую разметку высвобожденного пространства и оптимизацию таблиц, настроим запуск таковой вручную, например поздним вечером, когда уже никого нет на рабочем месте и некому рассматривать графики и таблицы:
# cat /etc/crontab
….# Запуск “vacuumdb” каждый день в 22:01
1 22 * * * root vacuumdb -U postgres –quiet –analyze –dbname=zabbix &
В примере выше мы запустили утилиту “vacuumdb” в режиме параллельного с клиентскими обращениями исполнения, без перераспределения данных, лишь с разметкой высвобожденного пространства как готового к использованию и анализом структуры для оптимизации запросов к таблицам.
Ежедневный проход утилиты позволит стабилизировать размер базы на определённом уровне, но не даст выигрыша в доступном дисковом пространстве после массированного удаления данных, как этого хотелось бы иногда ожидать.
Для высвобождения дискового пространства следует провести более глубокое “вакуумирование”, которое буквально высвободит занятое пустыми блоками дисковое пространство; но для этого потребуется блокировка базы от клиентских обращений – такое можно себе позволить лишь изредка, во время профилактики или реструктуризации:
# vacuumdb -U postgres –verbose –analyze –full –dbname=zabbix
В качестве дополнительной пищи для размышлений, применяющим PostgreSQL (или даже MySQL) в качестве СУБД для Zabbix в качестве сервера мониторинга с тысячами субъектов мониторинга, рекомендую присмотреться к секционированию (partition) таблиц, например по дням или месяцам, что позволит повысить производительность самой СУБД в работе и упростит управление архивами данных, позволяя при необходимости просто удалять старые куски таблицы.
Источник: http://www.umgum.com/zabbix-housekeeper-postgresql-vacuum
Оптимизация настроек Zabbix
Стандартные настройки в zabbix, не всегда хорошо работают и их необходимо тюнить под свои нужды. Я собрал в данной статье, основные параметры для оптимизации. Возможно, — это не все и вы знаете больше, но я постараюсь максимизировать.
Настройка кеша
Для оптимизации заббикс сервера, стоит увеличить размер кеша, для этого — открываем:
# vim /etc/zabbix/zabbix_server.conf
Находим строку «CacheSize» и увеличиваем его.
### Option: CacheSize # Size of configuration cache, in bytes. # Shared memory size for storing host, item and trigger data. # # Mandatory: no # Range: 128K-8G # Default: CacheSize=256M
Я увеличил до 256M. При надобности, можно добавить.
Zabbix discoverer processes more than 75% busy
Недавно получил алерт в заббиксе:
Zabbix discoverer processes more than 75% busy
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Ищем строку с опцией «StartDiscoverers» и увеличиваем данный параметр:
### Option: StartDiscoverers # Number of pre-forked instances of discoverers. # # Mandatory: no # Range: 0-250 # Default: StartDiscoverers=5
Я, опцию StartDiscoverers увеличил до 5. На этом настройка заканчивается, нужно сохранить конфиг и перезагрузить zabbix сервер:
# service zabbix-server restart
Можно увидеть мой наглядный пример:
Если после добавления хостов ( с разными подсетями) вы увидите что снова сработал этот триггер, то нужно увеличить StartDiscoverers.
Zabbix icmp pinger processes more than 75% busy
Недавно получил алерт в заббиксе:
Zabbix icmp pinger processes more than 75% busy
Данное сообщение, говорит — что процесс(ы) выполняющие ping по хостам, перегружены.
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Ищем строку с опцией «StartPingers» и увеличиваем данный параметр:
### Option: StartPingers # Number of pre-forked instances of ICMP pingers. # # Mandatory: no # Range: 0-1000 # Default: StartPingers=5
Я, опцию StartPingers увеличил до 5, тем самым — я увеличил количество процессов выполняющих ICMP Ping.
На этом настройка заканчивается, нужно сохранить конфиг и перезагрузить zabbix сервер:
# service zabbix-server restart
Zabbix poller processes more than 75% busy
poller — это процесс который опрашивает агентов.
Данный параметр стоит увеличивать в 2- случаях:
- Большая сеть
- Есть много недоступных ресурсов и они мониторятся.
Как исправить?
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Ищем строку с опцией «StartPollers» и увеличиваем данный параметр:
### Option: StartPollers # Number of pre-forked instances of pollers. # # Mandatory: no # Range: 0-1000 # Default: StartPollers=5
Я установил данный параметр в 5. Если очень будет худо, то увеличиваем его до 20. Ничто не приходит бесследно, увеличение процессов ведет к увеличение потребления ресурсов.
После этого, вы можете получить:
Zabbix unreachable poller processes more than 75% busy
Если видите у себя данное сообщение ( алерт, сработанный триггер), открываем конфиг:
# vim /etc/zabbix/zabbix_server.conf
Ищем строку с опцией «StartPollersUnreachable» и увеличиваем данный параметр:
### Option: StartPollersUnreachable # Number of pre-forked instances of pollers for unreachable hosts (including IPMI and Java). # At least one poller for unreachable hosts must be running if regular, IPMI or Java pollers # are started. # # Mandatory: no # Range: 0-1000 # Default: # StartPollersUnreachable=1
PS: У меня данный параметр используется по умолчанию и я его не трогал ( не было ошибок).
Имеется вероятность того, что перестанет хватать коннекщенов для БД, то надо увеличивать лимит подключений.
Zabbix housekeeper processes more than 75% busy
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
И приводим к виду:
HousekeepingFrequency=1 MaxHousekeeperDelete=100
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
Zabbix busy timer processes, in %
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Переменную укажу позже (не знаю какая)!
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
Zabbix busy escalator processes, in %
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Переменную укажу позже (не знаю какая)!
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
Zabbix busy alerter processes, in %
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Переменную укажу позже (не знаю какая)!
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
Zabbix busy configuration syncer processes, in %
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Находим и изменяем:
HistoryCacheSize=
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
Zabbix busy db watchdog processes, in %
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Переменную укажу позже (не знаю какая)!
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
Zabbix busy history syncer processes, in %
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Находим и изменяем:
HistoryCacheSize= CacheSize=
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
Zabbix busy self-monitoring processes, in %
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Переменную укажу позже (не знаю какая)!
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
Zabbix busy http poller processes, in %
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Находим и меняем параметр:
StartHTTPPollers=
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
Zabbix busy java poller processes, in %
Это можно исправить, откроем zabbix_server.conf конфиг-файл:
# vim /etc/zabbix/zabbix_server.conf
Находим и меняем параметр:
StartJavaPollers=
Сохраняем файл и перезагружаем zabbix:
# service zabbix-server restart
А на этом, у меня все и статья «Оптимизация настроек Zabbix» завершена.
Источник: http://linux-notes.org/optimizatsiya-nastroek-zabbix/
Labusman.ru Zabbix. Postgresql. Секционирование таблиц
В целях повышения производительности Zabbix был осуществлен переход базы данных с Mysql на PostgreSQL.
Первое время после перехода заббикс радовал производительностью да так, что набравшись смелости, было добавлено ещё пару десятков устройств по сотне элементов на каждый.
И все было хорошо, но спустя некоторое время (а именно время устаревания данных в настройках объектов) база ушла в режим задумчивости, съедая почти всё IO.
Ладно – перенесём базу на машину “посильнее”. После переноса отпустило и полетел пошел процесс добавления новых узлов.
Нагрузка на IO, оказалось, полностью зависила от внутреннего процесса зачистки истории HouseKeeper в забиксе. Причем на более слабой машине этот процесс не заканчивался сутками – сжирая всё IO, а на новой запускался каждые 2 часа и напрягал лишь по 10 минут, завершался не вызывая заметных неудобств.
Узлов становилось всё больше и плавненько довело длительность прохода HouseKeeper до 4 часов. Да ну его — полез разбираться.
Все операции по оптимизации базы, подкручивании настроек HouseKeeper коих всего 2 – пауза и количество удаляемых данных – ничего значимого не дало. Либо тупим, либо не удаляем всё и база растет. Обновление забикса до 2.4.
4 тоже ситуацию не поменяло. Любопытно, что при стандартной работе IO топчется на 1% а вот при HouseKeeper все 80%.
Великий гугл подсказал, что можно сегментировать (партицировать) таблицы с историей на подтаблицы, в которых содержится все го лишь по дню данных и все го лишь за пару секунд удалять лишние таблицы при наступлении часа Х.
Есть даже готовые мануалы по этому счастью, но хочется разобраться поглубже в этом механизме да и структура базы в этих мануалах несколько различаются от того, что есть у меня. Для экспериментов выбрана база данных Postgresql на слабом сервере.
Причем хочется не потерять старые данные и рассортировать их тоже.
Для начала выделим таблицы, которые будем разбивать. Просто выделим лидеров по количеству строк: select relname, n_live_tup from pg_stat_user_tables;
У меня в неоспоримые лидер выбились: history_uint, events, trends, trends_uint, history, history_text. Для нормального разбиения необходимо, что-бы в каждой таблице было поле со временем (по сути можно и по другим полям делить – но логичней по времени).
У меня во всех таблицах оказалось поле clock. По нему и будем делить. Для унификации функций поищем ещё “общих” полей для построения индекса.
Во всех таблицах кроме events есть поле itemid, а вот с таблицей events создавать отдельную строчку в функции я поленился — поэтому будем без неё (в листинге помечено зелёным).
По теории нам необходимо добавить пару функций в постгре, на основании которых будут производиться записи в подтаблицы и их создание при необходимости. Запросы же будут работать прозрачно за счёт наследования таблиц. Больше в теорию углубляться не будем — мне лично больше нравиться практика.
Итак за дело!
Перейдем к созданию функций. Оформлять будем в отдельный файл. Вот Вам пример — для осознания смотрите комментарии:
func.sql:
–удаляем коль с первого раза не вышло написать
–DROP SCHEMA partitions CASCADE;
CREATE SCHEMA partitions AUTHORIZATION zabbix;
–обьявляем общую функцию для работы создания секционных таблиц, первый параметр имя таблицы (без даты разумеется),
— второй daily/monthly – какое разбиение используем
— третий – дата для новой таблицы
DROP FUNCTION create_zbx_partitions(text,text,timestamp);
CREATE OR REPLACE FUNCTION create_zbx_partitions(part TEXT ,part_mode TEXT,timecr TIMESTAMP DEFAULT CURRENT_TIMESTAMP) RETURNS VOID AS $$
— Обьявление переменных
DECLARE
current_check TEXT;
next_check TEXT;
next_partition TEXT;
created_partition TEXT;
name RECORD;
cons RECORD;
— Поехали!
BEGIN
— Вычислить требуется:
— next_partition – какое имя подтаблицы создавать (без имени подтаблицы – просто _дата)
— current_check – для проверки поле clock в новой таблице должно быть больше равно этого
— next_check – для проверки поле clock в новой таблице должно быть меньше этого
— Если разбиение по дням вычисляем названия для создания новой подтаблицы.
IF part_mode = 'daily' THEN
SELECT EXTRACT(epoch FROM date_trunc('day',timecr) at time zone 'UTC' ) INTO current_check;
SELECT EXTRACT(epoch FROM date_trunc('day',timecr + INTERVAL '1 day') at time zone 'UTC' ) INTO next_check;
SELECT TO_CHAR(timecr,'_yyyymmdd') INTO next_partition;
END IF;
— Если разбиение по месяцам вычисляем названия для создания новой подтаблицы.
IF part_mode = 'monthly' THEN
SELECT EXTRACT(epoch FROM date_trunc('month',timecr) at time zone 'UTC' ) INTO current_check;
SELECT EXTRACT(epoch FROM date_trunc('month',timecr + INTERVAL '1 month' ) at time zone 'UTC' ) INTO next_check;
SELECT TO_CHAR(timecr,'_yyyymm') INTO next_partition;
END IF;
— ну раз посчитали — собственно заведём секцию
created_partition:='partitions.' || part || next_partition;
EXECUTE 'create table if not exists ' || created_partition ||' (check ( clock >= ' || current_check || ' and clock < ' || next_check || ')) INHERITS (' || part || ')';
— и индекс
EXECUTE 'CREATE INDEX “'|| part || next_partition || '_1” on ' || created_partition || ' (itemid,clock)';
END;
— Ну а тут собственно внедрение новых данных в работе
$$ LANGUAGE plpgsql;
— удаляем коль с первого раза не вышло написать
— DROP FUNCTION dynamic_insert_trigger() CASCADE;
CREATE OR REPLACE FUNCTION dynamic_insert_trigger()
RETURNS TRIGGER AS $$
DECLARE
timeformat TEXT;
insert_sql TEXT;
BEGIN
— посмотрим как нам в дату все организовать надо
IF TG_ARGV[0] = 'daily' THEN
timeformat:='_yyyymmdd';
ELSIF TG_ARGV[0] = 'monthly' THEN
timeformat:='_yyyymm';
END IF;
— Пробуем с лету вставить новую запись в секцию
EXECUTE 'INSERT INTO partitions.' || TG_TABLE_NAME || TO_CHAR(TO_TIMESTAMP(NEW.clock) at time zone 'UTC',timeformat) || ' SELECT ($1).*' USING NEW;
RETURN NULL;
EXCEPTION
WHEN undefined_table THEN
— если нужной секции нет вызовем функцию которая её создаст
EXECUTE 'SELECT create_zbx_partitions(' || quote_literal(TG_TABLE_NAME) ||','|| quote_literal(TG_ARGV[0]) ||' ,'|| quote_literal(TO_TIMESTAMP(NEW.clock) at time zone 'UTC')||')';
— и опять вставим новую запись
EXECUTE 'INSERT INTO partitions.' || TG_TABLE_NAME || TO_CHAR(TO_TIMESTAMP(NEW.clock) at time zone 'UTC',timeformat) || ' SELECT ($1).*' USING NEW;
RETURN NULL;
END;
— осталось навешать триггеры на нужные таблицы
–обратите внимание – опять происходит выбор daily/mountly
$$ LANGUAGE plpgsql;
CREATE TRIGGER history_trigger
BEFORE INSERT ON history
FOR EACH ROW EXECUTE PROCEDURE dynamic_insert_trigger('daily');
CREATE TRIGGER history_uint_trigger
BEFORE INSERT ON history_uint
FOR EACH ROW EXECUTE PROCEDURE dynamic_insert_trigger('daily');
CREATE TRIGGER trends_trigger
BEFORE INSERT ON trends
FOR EACH ROW EXECUTE PROCEDURE dynamic_insert_trigger('daily');
CREATE TRIGGER trends_uint_trigger
BEFORE INSERT ON trends_uint
FOR EACH ROW EXECUTE PROCEDURE dynamic_insert_trigger('daily');
CREATE TRIGGER history_text_trigger
BEFORE INSERT ON history_text
FOR EACH ROW EXECUTE PROCEDURE dynamic_insert_trigger('daily');
Переходим к накатыванию. К сожалению zabbix-server и frontend придется на время выключить. Некоторый промежуток времени мы потеряем. Далее мы хотим сохранить старые данные. Сделаем дампы разбиваемых таблиц (pg_dump) и отложим их в сторонку.
Теперь необходимо очистить разбиваемые таблицы: TRUNCATE TABLE history; и т. д. После этого подкармливаем наш скрипт базе – смотрим, дабы ни на что не ругался: psql -f func.sql Теперь вкатываем сделанные дампы таблиц обратно: psql < имя_дампа.sql. По окончании всех накатываний запускаем zabbix-server и frontend и смотрим.
В моей конфигурации таблица events не разбивается – поэтому уже в веблице – “Администрирование/Общие/Очистка истории” я оставил единственную галочку “Активировать внутреннюю очистку истории ” только возле “События и оповещения” . Работа Husekeeper не чувствуется! (housekeeper [deleted 0 hist/trends, 0 items, 1100 events, 0 sessions, 0 alarms, 0 audit items in 0.079623 sec, idle 2 hour(s)] ).
Зашел я полюбоваться длинными графиками после всего этого действия и ничего не увидел. Заббикс просто не давал поставить дату на графике раньше, чем пару часов назад. Оказалось во фронтенде есть хитрая функция, которая проверяет доступность данных – придется её изменить. Идем в файлик /var/www/zabbix/include/graphs.inc.
php (ну или где у Вас фронтенд). Находим функцию function get_min_itemclock_by_itemid($itemIds) и перед последним return вставляем return 0. Либо, если по красивше, вместо 0 ставим timestamp начальной даты.
Когда не будет разрывов в данных (через столько времени за сколько вы хотите видеть статистику) — строчку убираем.
По поводу удаления старых данных. Автоматизация в планы не входит и я планирую удалять только если уже действительно будет занято непомерно места. Удаление заключается всего лишь в удалении “старых” секций. Их имена содержат в себе дату — так, что никаких разночтений быть не может (DROP TABLE partition.history_20010101;) Есть желание скриптовать — да хоть в кроне. Всем удачи.
Источник: http://labusman.ru/article/view/633